Código
pacman::p_load(rio, digest, stargazer, sjPlot, codebook, summarytools, dplyr, tidyr,
tidyLPA, lme4, ggplot2, ggeffects, skimr, table1, patchwork, here, kableExtra, ggthemes, tidyverse)
options(scipen = 999)Esta sección pretende documentar todas las decisiones tomadas durante el procesamiento de las bases de datos, desde su limpieza hasta la construcción de la base final. En principio, se trabajará con dos bases: la que viene con el promedio calculado a partir de los semestres cursados por el estudiante (1), y la base que contiene las notas desagregadas por curso (2). A partir de esto, se generará una base final que contenga las dos maneras de visualizar las notas, y posteriormente se realizará una comparación de los promedios (el por defecto y uno calculado a partir de las notas de curso) para comprobar si son equivalentes 1. Por último, se presentarán algunos resultados descriptivos orientados a encontrar diferencias en los promedios de las distintas carreras.
pacman::p_load(rio, digest, stargazer, sjPlot, codebook, summarytools, dplyr, tidyr,
tidyLPA, lme4, ggplot2, ggeffects, skimr, table1, patchwork, here, kableExtra, ggthemes, tidyverse)
options(scipen = 999)En orden de realizar un procedimiento lo más pulcro posible, se tomó la decisión de trabajar inicialmente con un subset de datos para luego replicar el mismo proceso con los datos completos. El subset con el cual se trabajará considera a los alumnos de Sociología de la cohorte 2024 (N = 101). Cabe mencionar que, para generar este conjunto de datos, se realizó un procesamiento previo el cual se encuentra en “proc/proc-subset.qmd”. Las modificaciones principales fueron la estandarización del puntaje de PSU/PAES, la selección de variables y el filtro por carrera y cohorte.
Nota: Al estar trabajando en el entorno, es necesario eliminar los saltos de ruta (../../../) para cargar las bases y poder trabajar con ellas. EN cambio, para que el documento renderice correctamente, hay que dejarlas tal como están. Esto se debe a un desajuste entre la dirección del documento y la renderización del mismo. Pronto se resolverá para que el código sea totalmente reproducible.
nota_final_sub <- readRDS("../../../input/data/proc_data/nota_unica_socio.rds")
notas_cursos <- readRDS("../../../input/data/proc_data/notas_cursos.rds")La base nota_final_sub es la base que contiene la nota final del estudiante, es decir, la nota promediada a partir de todos los semestres cursados en la carrera. Está en formato wide ya se encuentra filtrada por los estudiantes de sociología.
La base notas_cursos considera las notas desagregadas por cada cátedra que ha cursado un estudiante en cada semestre. Está en formato long.
Hay un patrón en la base donde cada caso puede tener cursos repetidos, donde algunos cuentan con valor 0, y otros con la nota real. Además, se sabe que tanto las notas 0 y 1 no son valores válidos. Tomando en cuenta esto, se decidió eliminar a los cursos repetidos y quedarnos con los cursos que tienen una nota mayor que 1.
notas_cursos_sub <- notas_cursos %>%
filter(NOMBRE2 == "Sociología") %>%
group_by(RUT, CARRERA) %>%
arrange(NOTA.FINAL.CURSO) %>%
filter(NOTA.FINAL.CURSO > 1) %>%
slice(1) %>%
ungroup()Ahora pasamos a transformar la base de formato long a wide, con tal de que cada curso sea una columna. Además, se intentó mantener el semestre y el año en que la persona cursó cada cátedra, lo que quedó consignado en la segunda parte del chunk. De momento seguiremos trabajando con la base que contiene sólo las notas por curso, pues es más fiel al formato wide y nos facilitará la comparación con la nota final de la otra base.
cursos_wide_sub <- notas_cursos_sub %>%
pivot_wider(
id_cols = RUT,
names_from = CARRERA, # Los cursos se convierten en nombres de columnas
values_from = NOTA.FINAL.CURSO,
names_prefix = "curso_"
)
#df_wide_semestral <- notas_cursos %>%
# pivot_wider(
# id_cols = c(RUT, ANO, TIPOS.PERIODOS),
# names_from = CARRERA,
# values_from = NOTA.FINAL.CURSO,
# names_prefix = "curso_"
# )Filtramos la base con la nota por defecto considerando solamente estudiantes de la cohorte 2024.
nota_final_sub <- nota_final_sub %>%
filter(cohorte == 2024)Se procede a realizar el merge de las bases a partir del RUT. La unión se realiza con este código ya que permite incluir las variables de ambas bases de datos, aportando a una mayor información para los análisis posteriores.
socio_2024 <- nota_final_sub %>%
inner_join(cursos_wide_sub, by = "RUT")Al observar los N de la base final en comparación de la base que contiene la nota final, se evidencia la pérdida de 2 casos. Para encontrar la fuente de los casos faltantes vemos, asumimos que hay casos que se encuentran en una base y en la otra no.
casos_perdidos <- anti_join(nota_final_sub, socio_2024, by = "RUT")
nrow(casos_perdidos)[1] 2Efectivamente hay 2 casos que están registrados en la base con la nota promediada, pero que no forman parte de la base desagregada de notas. Uno de esos casos se retiro de la carrera, por lo que esa podría ser la razón de porqué no se encuentra en la base de datos de notas por curso.
Como contamos con el promedio final en bruto, y ahora con las notas desagregadas por cursos, realizaremos un análisis para comprobar si se condicen ambos promedios y, así, verificar la información que venía desde la base construida.
Para ello, primero nos aseguraremos de distinguir las dos variables de promedios.
socio_2024 <- socio_2024 %>%
rename(promedio_bruto = PROMEDIO)columnas_cursos <- grep("^curso_", names(socio_2024), value = TRUE)
socio_2024[, columnas_cursos] <- lapply(socio_2024[, columnas_cursos], as.numeric)
socio_2024$promedio_calculado <- rowMeans(socio_2024[, columnas_cursos], na.rm = TRUE)
socio_2024$mean_dif <- socio_2024$promedio_bruto - socio_2024$promedio_calculado
head(socio_2024$mean_dif, 10) [1] 0.26363636 0.08909091 0.88454545 -0.23153846 0.10833333 0.00000000
[7] 0.19818182 -0.13333333 0.21333333 0.10727273Se puede apreciar que, al menos en los primeros diez casos, existen diferencias entre el promedio integrado en la base de datos y el promedio que calculamos nosotros. A pesar de ello, este resultado no entrega información concluyente, por lo que ahondaremos en esto calculando la correlación entre ambos promedios. Mientras más alta la correlación, los promedios deberían estar más cercano el uno al otro.
cor(x = socio_2024$promedio_bruto,
y = socio_2024$promedio_calculado,
use = "complete.obs")[1] 0.1768021cor.test(
x = socio_2024$promedio_bruto,
y = socio_2024$promedio_calculado,
use = "complete.obs"
)
Pearson's product-moment correlation
data: socio_2024$promedio_bruto and socio_2024$promedio_calculado
t = 1.7692, df = 97, p-value = 0.08001
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
-0.02135505 0.36159332
sample estimates:
cor
0.1768021
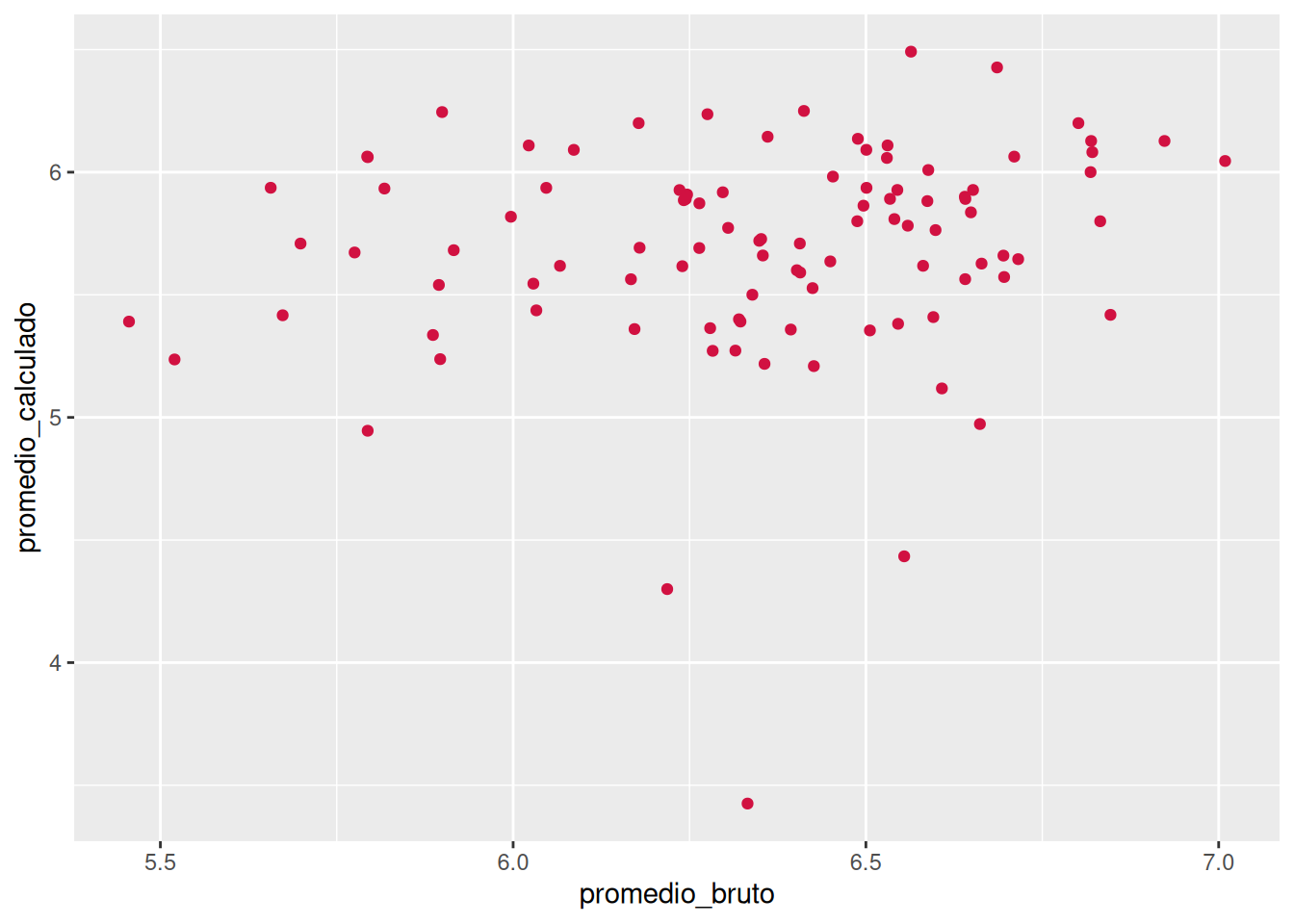
Al observar un valor tan bajo en la correlación de los promedios (\(r = 0.18\)), podemos plantear que hay un desajuste entre el promedio en bruto y el promedio calculado, lo cual se condice con la falta de un patrón claro en la nube de puntos. Sin embargo, el resultado no es significativo (\(p = 0.08\)). Para ahondar en este resultado, aplicaremos el mismo proceso pero a un set de datos de la carrera de sociología considerando todas las cohortes disponibles, con tal de ganar poder explicativo.
Ahora, replicaremos el procesamiento anterior para cada carrera de la Facultad, con el objetivo de ampliar el análisis y realizar un diagnóstico con la mayor cantidad de información posible.
nota_final_socio <- readRDS("../../../input/data/proc_data/nota_unica_socio.rds")
notas_cursos <- readRDS("../../../input/data/proc_data/notas_cursos.rds")notas_cursos_socio <- notas_cursos %>%
filter (NOMBRE2 == "Sociología") %>%
group_by(RUT, CARRERA) %>%
arrange(NOTA.FINAL.CURSO) %>%
filter(NOTA.FINAL.CURSO > 1) %>%
slice(1) %>%
ungroup()cursos_wide_socio <- notas_cursos_socio %>%
pivot_wider(
id_cols = RUT,
names_from = CARRERA, # Los cursos se convierten en nombres de columnas
values_from = NOTA.FINAL.CURSO,
names_prefix = "curso_"
)Para este caso, consideramos desde la cohorte 2021 hasta la 2024 debido a que son los años que contiene la base de notas por curso, es decir, son los datos con los que se puede trabajar apropiadamente al realizar el merge de las bases.
nota_final_socio <- nota_final_socio %>%
filter(cohorte %in% c(2021, 2022, 2023, 2024))socio_completa <- nota_final_socio %>%
inner_join(cursos_wide_socio, by = "RUT")casos_perdidos_socio <- anti_join(nota_final_socio, socio_completa, by = "RUT")
nrow(casos_perdidos_socio)[1] 5Posterior al merge de las bases, se pierden 5 observaciones, es decir, hay 5 individuos que están en la base que contiene el promedio entregado por UCampus pero no están registrados en la base que contiene las notas por curso. Al revisar los datos, se halló que uno de los 5 casos que se pierde renunció a la carrera, por lo que eso puede explicar el porqué se pierde su registro en la base que contiene notas por curso. Los 4 restantes tienen una situación académica activa, es decir, se encuentran matriculados, y no se encontró ningún patrón que permitiera identificar la razón de su pérdida.
socio_completa <- socio_completa %>%
rename(promedio_bruto = PROMEDIO)columnas_cursos_socio <- grep("^curso_", names(socio_completa), value = TRUE)
socio_completa[, columnas_cursos_socio] <- lapply(socio_completa[, columnas_cursos_socio], as.numeric)
socio_completa$promedio_calculado <- rowMeans(socio_completa[, columnas_cursos_socio], na.rm = TRUE)
socio_completa$mean_dif <- socio_completa$promedio_bruto - socio_completa$promedio_calculador_socio <- cor(x = socio_completa$promedio_bruto,
y = socio_completa$promedio_calculado,
use = "complete.obs")nota_unica_psico <- readRDS("../../../input/data/proc_data/nota_unica_psico.rds")notas_cursos_psico <- notas_cursos %>%
filter (NOMBRE2 == "Psicología") %>%
group_by(RUT, CARRERA) %>%
arrange(NOTA.FINAL.CURSO) %>%
filter(NOTA.FINAL.CURSO > 1) %>%
slice(1) %>%
ungroup()cursos_wide_psico <- notas_cursos_psico %>%
pivot_wider(
id_cols = RUT,
names_from = CARRERA, # Los cursos se convierten en nombres de columnas
values_from = NOTA.FINAL.CURSO,
names_prefix = "curso_"
)nota_unica_psico <- nota_unica_psico %>%
filter(cohorte %in% c(2021, 2022, 2023, 2024))psico_completa <- nota_unica_psico %>%
inner_join(cursos_wide_psico, by = "RUT")casos_perdidos_psico <- anti_join(nota_unica_psico, psico_completa, by = "RUT")
nrow(casos_perdidos_psico)[1] 3Posterior al merge de las bases, se pierden 3 observaciones, es decir, hay 3 individuos que están en la base que contiene el promedio entregado por UCampus pero no están registrados en la base que contiene las notas de cada curso. Los 3 los estudiantes están matriculados, pero todos coinciden en que pertenecen a la cohorte 2024. Además, uno de ellos no tiene RUT ni ninguna información sociodemográfica válida, y su ingreso a la universidad se señala como “Est. medios extranjeros”, por lo que esto podría ser razón de su pérdida.
psico_completa <- psico_completa %>%
rename(promedio_bruto = PROMEDIO)columnas_cursos_psico <- grep("^curso_", names(psico_completa), value = TRUE)
psico_completa[, columnas_cursos_psico] <- lapply(psico_completa[, columnas_cursos_psico], as.numeric)
psico_completa$promedio_calculado <- rowMeans(psico_completa[, columnas_cursos_psico], na.rm = TRUE)
psico_completa$mean_dif <- psico_completa$promedio_bruto - psico_completa$promedio_calculador_psico <- cor(x = psico_completa$promedio_bruto,
y = psico_completa$promedio_calculado,
use = "complete.obs")nota_unica_educa <- readRDS("../../../input/data/proc_data/nota_unica_educa.rds")notas_cursos_educa <- notas_cursos %>%
filter (NOMBRE2 == "Pedagogía en Educación Parvularia") %>%
group_by(RUT, CARRERA) %>%
arrange(NOTA.FINAL.CURSO) %>%
filter(NOTA.FINAL.CURSO > 1) %>%
slice(1) %>%
ungroup()cursos_wide_educa <- notas_cursos_educa %>%
pivot_wider(
id_cols = RUT,
names_from = CARRERA, # Los cursos se convierten en nombres de columnas
values_from = NOTA.FINAL.CURSO,
names_prefix = "curso_"
)nota_unica_educa <- nota_unica_educa %>%
filter(cohorte %in% c(2021, 2022, 2023, 2024))educa_completa <- nota_unica_educa %>%
inner_join(cursos_wide_educa, by = "RUT")casos_perdidos_educa <- anti_join(nota_unica_educa, educa_completa, by = "RUT")
nrow(casos_perdidos_educa)[1] 0Posterior al merge de las bases, no se pierden casos.
educa_completa <- educa_completa %>%
rename(promedio_bruto = PROMEDIO)columnas_cursos_educa <- grep("^curso_", names(educa_completa), value = TRUE)
educa_completa[, columnas_cursos_educa] <- lapply(educa_completa[, columnas_cursos_educa], as.numeric)
educa_completa$promedio_calculado <- rowMeans(educa_completa[, columnas_cursos_educa], na.rm = TRUE)
educa_completa$mean_dif <- educa_completa$promedio_bruto - educa_completa$promedio_calculador_educa <- cor(x = educa_completa$promedio_bruto,
y = educa_completa$promedio_calculado,
use = "complete.obs")nota_unica_antropo <- readRDS("../../../input/data/proc_data/nota_unica_antropo.rds")notas_cursos_antropo <- notas_cursos %>%
filter (NOMBRE2 == "Licenciatura en Antropología con mención Arqueología") %>%
group_by(RUT, CARRERA) %>%
arrange(NOTA.FINAL.CURSO) %>%
filter(NOTA.FINAL.CURSO > 1) %>%
slice(1) %>%
ungroup()cursos_wide_antropo <- notas_cursos_antropo %>%
pivot_wider(
id_cols = RUT,
names_from = CARRERA, # Los cursos se convierten en nombres de columnas
values_from = NOTA.FINAL.CURSO,
names_prefix = "curso_"
)nota_unica_antropo <- nota_unica_antropo %>%
filter(cohorte %in% c(2021, 2022, 2023, 2024))antropo_completa <- nota_unica_antropo %>%
inner_join(cursos_wide_antropo, by = "RUT")casos_perdidos_antropo <- anti_join(nota_unica_antropo, antropo_completa, by = "RUT")
nrow(casos_perdidos_antropo)[1] 266tabla_antropo_perdidos <- casos_perdidos_antropo %>%
group_by(cohorte) %>%
summarise(
N = n(),
.groups = "drop"
)| Año | N total |
|---|---|
| 2021 | 51 |
| 2022 | 50 |
| 2023 | 53 |
| 2024 | 112 |
Posterior al merge de las bases, se pierden 266 casos. Considerando que la base con la nota por defecto de Antropología tiene un N = 392, esto quiere decir que se están perdiendo cerca del 68% de los casos, lo cual tiene implicancias directas en los análisis. Sin embargo, solamente un caso no está matriculado, por lo que casi el total de los casos que se pierden no se debe a su situación académica. Al observar la tabla, se evidencia un patrón en la cantidad de casos entre las cohortes 2021 y 2023, perdiéndose aproximadamente 50 casos en cada una, mientras que la cohorte 2024 marca la excepción al perderse más de 100.
antropo_completa <- antropo_completa %>%
rename(promedio_bruto = PROMEDIO)columnas_cursos_antropo <- grep("^curso_", names(antropo_completa), value = TRUE)
antropo_completa[, columnas_cursos_antropo] <- lapply(antropo_completa[, columnas_cursos_antropo], as.numeric)
antropo_completa$promedio_calculado <- rowMeans(antropo_completa[, columnas_cursos_antropo], na.rm = TRUE)
antropo_completa$mean_dif <- antropo_completa$promedio_bruto - antropo_completa$promedio_calculador_antropo <- cor(x = antropo_completa$promedio_bruto,
y = antropo_completa$promedio_calculado,
use = "complete.obs")n_socio <- socio_completa %>%
group_by(cohorte) %>%
summarise(N = n(), .groups = "drop") %>%
mutate(Carrera = "Sociología")
n_psico <- psico_completa %>%
group_by(cohorte) %>%
summarise(N = n(), .groups = "drop") %>%
mutate(Carrera = "Psicología")
n_trabajo <- trabajo_completa %>%
group_by(cohorte) %>%
summarise(N = n(), .groups = "drop") %>%
mutate(Carrera = "Trabajo Social")
n_educa <- educa_completa %>%
group_by(cohorte) %>%
summarise(N = n(), .groups = "drop") %>%
mutate(Carrera = "Educación")
n_antropo <- antropo_completa %>%
group_by(cohorte) %>%
summarise(N = n(), .groups = "drop") %>%
mutate(Carrera = "Antropología")
n_total <- bind_rows(
n_socio,
n_psico,
n_trabajo,
n_educa,
n_antropo
)
tabla_final_alt <- n_total %>%
pivot_wider(
names_from = cohorte,
values_from = N,
values_fill = 0
) %>%
arrange(Carrera)
tabla_final_alt <- tabla_final_alt %>%
mutate(
Total = rowSums(across(where(is.numeric)), na.rm = TRUE)
)| Carrera | 2021 | 2022 | 2023 | 2024 | Total |
|---|---|---|---|---|---|
| Antropología | 39 | 33 | 50 | 4 | 126 |
| Educación | 36 | 41 | 45 | 58 | 180 |
| Psicología | 111 | 109 | 106 | 115 | 441 |
| Sociología | 91 | 80 | 103 | 99 | 373 |
| Trabajo Social | 59 | 49 | 65 | 64 | 237 |
Tabla 5.1 presenta la distribución de casos disponibles para las cinco carreras según sus respectivas cohortes. Psicología y Sociología concentran el mayor número de observaciones a lo largo del período analizado, con aproximadamente 100 casos por año. En contraste, Trabajo Social exhibe una tendencia estable entre 2021 y 2024, con valores cercanos a los 50 casos anuales. Por su parte, Educación Parvularia y Antropología registran un volumen considerablemente menor de casos en comparación con las demás carreras. En el caso de Educación Parvularia, esta situación podría explicarse por una baja disponibilidad de observaciones de manera consistente en todas las cohortes, donde la cohorte con mayor número alcanza 58 casos. En Antropología, en cambio, la reducción se asocia principalmente a la pérdida de observaciones derivada del merge de las bases de datos.
tabla_promedios <- bind_rows(
socio_completa %>%
summarise(
Promedio_bruto = mean(promedio_bruto, na.rm = TRUE),
Promedio_calculado = mean(promedio_calculado, na.rm = TRUE)
) %>%
mutate(Carrera = "Sociología"),
psico_completa %>%
summarise(
Promedio_bruto = mean(promedio_bruto, na.rm = TRUE),
Promedio_calculado = mean(promedio_calculado, na.rm = TRUE)
) %>%
mutate(Carrera = "Psicología"),
trabajo_completa %>%
summarise(
Promedio_bruto = mean(promedio_bruto, na.rm = TRUE),
Promedio_calculado = mean(promedio_calculado, na.rm = TRUE)
) %>%
mutate(Carrera = "Trabajo Social"),
educa_completa %>%
summarise(
Promedio_bruto = mean(promedio_bruto, na.rm = TRUE),
Promedio_calculado = mean(promedio_calculado, na.rm = TRUE)
) %>%
mutate(Carrera = "Educación"),
antropo_completa %>%
summarise(
Promedio_bruto = mean(promedio_bruto, na.rm = TRUE),
Promedio_calculado = mean(promedio_calculado, na.rm = TRUE)
) %>%
mutate(Carrera = "Antropología")
) %>%
relocate(Carrera)| Carrera | Promedio_bruto | Promedio_calculado |
|---|---|---|
| Sociología | 6.39 | 5.81 |
| Psicología | 6.58 | 5.92 |
| Trabajo Social | 6.21 | 5.69 |
| Educación | 6.28 | 6.16 |
| Antropología | 6.35 | 5.90 |
Tabla 5.2 presenta los promedios por carrera, distinguiendo entre el promedio bruto y el promedio calculado a partir de las calificaciones de los cursos. Al considerar el promedio bruto, Psicología registra el valor más alto, con un promedio aproximado de 6.6, seguida por Sociología, Antropología, Educación Parvularia y Trabajo Social, en ese orden. Cabe destacar que, en este indicador, todas las carreras exhiben promedios superiores a 6.0.
En contraste, el promedio calculado evidencia una disminución generalizada respecto del promedio bruto en todas las carreras. En este escenario, Educación Parvularia es la única que mantiene un promedio superior a 6.0, mientras que Psicología, Sociología y Antropología se sitúan en torno a 5.9. Trabajo Social presenta el valor más bajo, con un promedio cercano a 5.7, posicionándose como la carrera con el menor desempeño en ambos indicadores analizados.
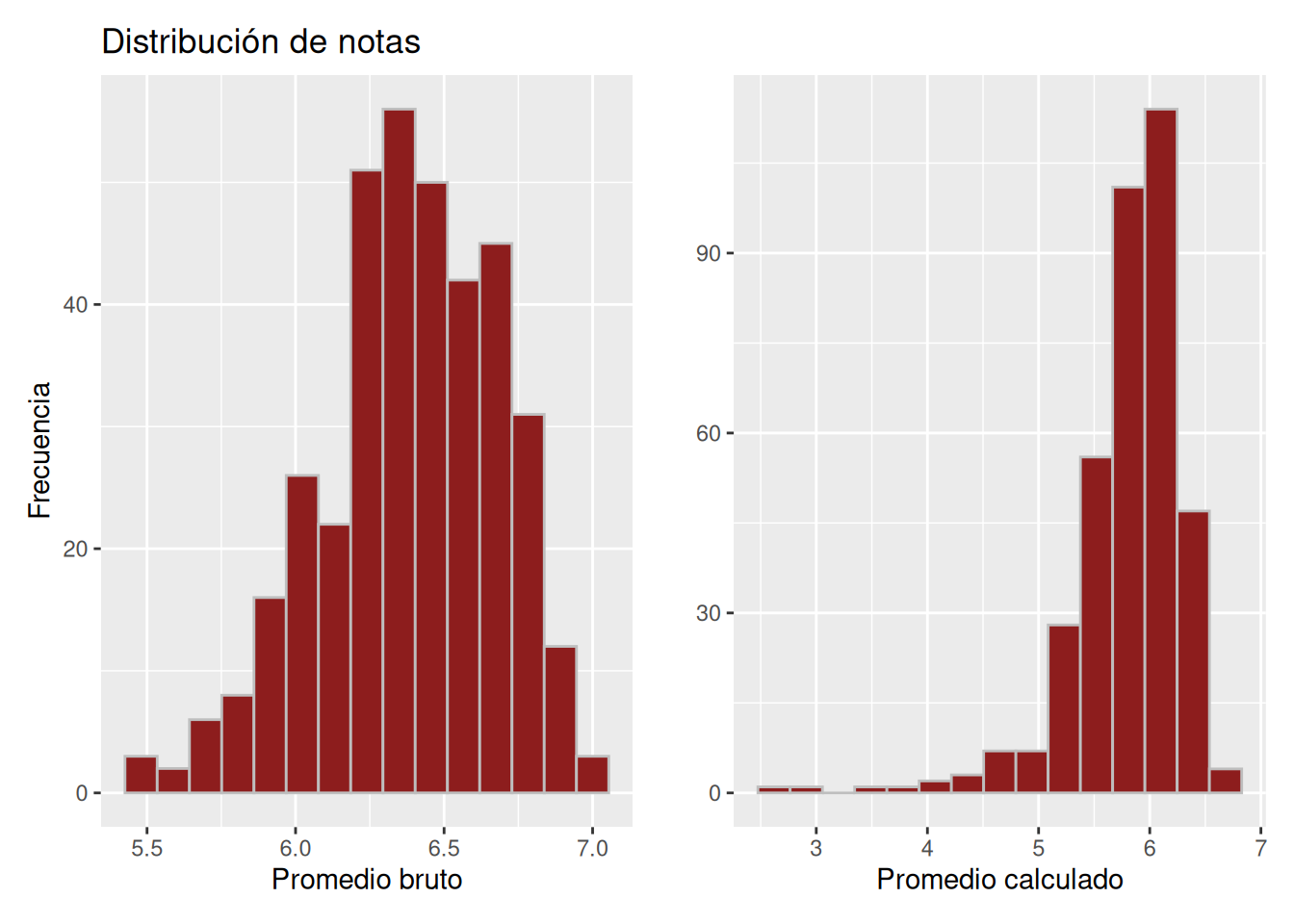
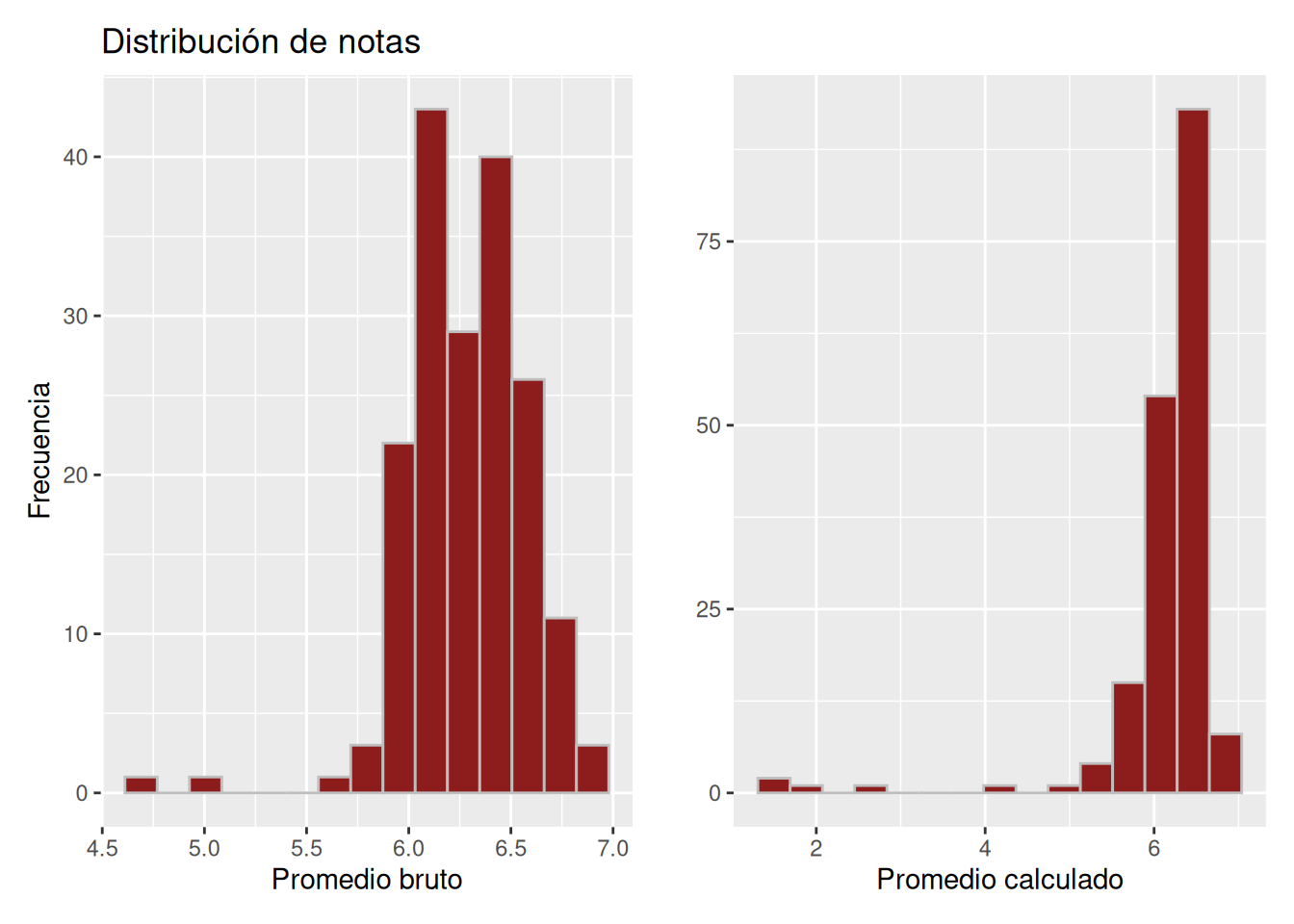
En el panel se presentan, para cada carrera, dos histogramas comparativos: a la izquierda se muestra la distribución del promedio bruto y a la derecha la del promedio calculado. En Figura 5.2, los promedios brutos se concentran entre 5.5 y 7.0; en contraste, aunque el promedio calculado mantiene una mayor densidad en el tramo superior de la escala, se observan valores que descienden hasta aproximadamente 3.0.
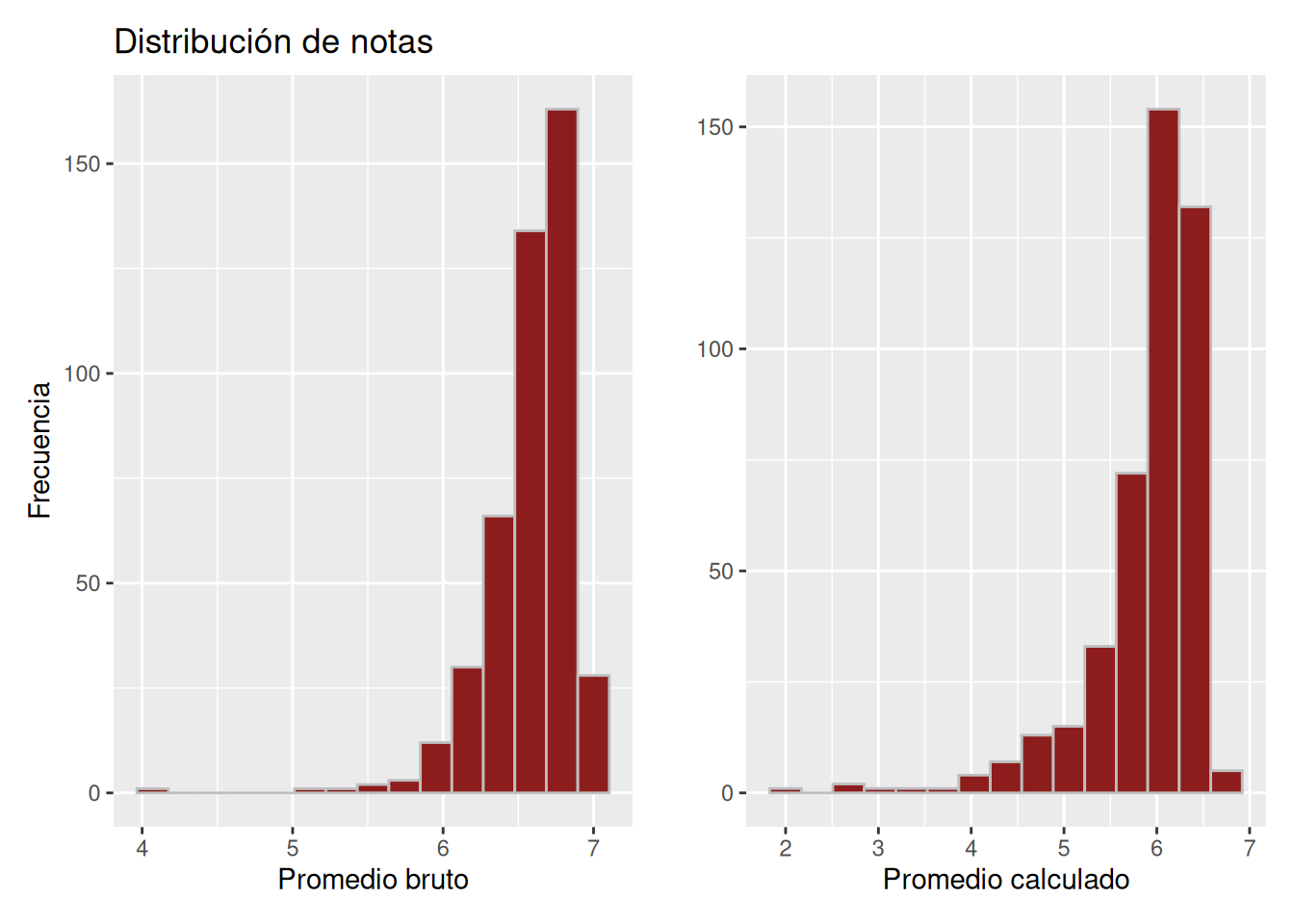
En Figura 5.3 y Figura 5.4, las distribuciones del promedio bruto y del promedio calculado presentan formas generales similares, con algunas diferencias relevantes. En Psicología, el promedio bruto mínimo se sitúa en torno a 4.0, seguido de un intervalo sin observaciones hasta aproximadamente 5.0. Un patrón comparable se identifica en Trabajo Social, donde el promedio bruto exhibe una brecha entre 3.0 y 5.0 sin casos registrados. No obstante, en el promedio calculado de Trabajo Social se observan valores inferiores a 2.0, junto con una mayor presencia de observaciones entre 2.0 y 5.0.
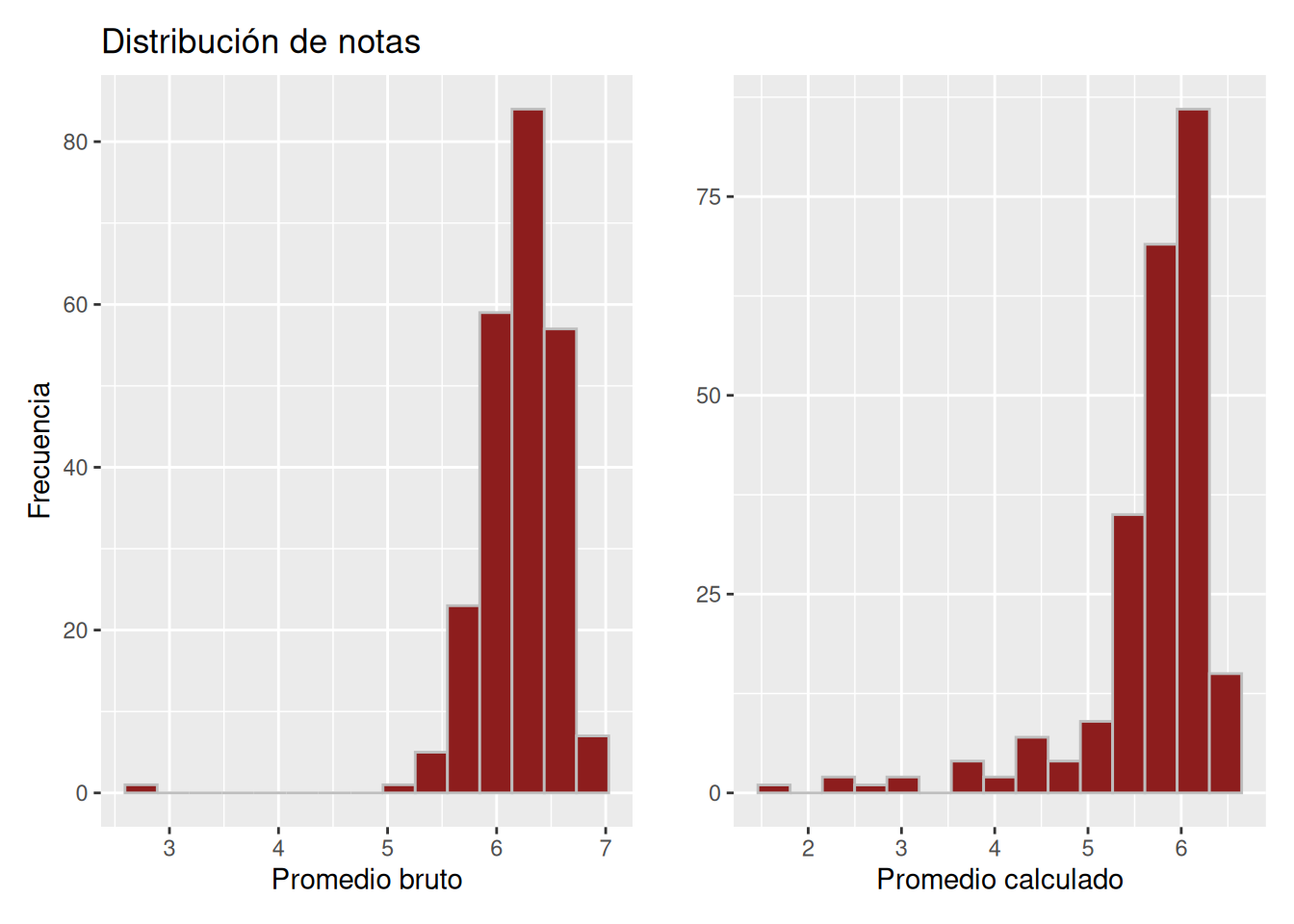
En Figura 5.5, los histogramas difieren de manera más marcada. En el promedio bruto, las calificaciones mínimas se sitúan alrededor de 5.0 y la mayor concentración se ubica entre 5.5 y 7.0. Por el contrario, el promedio calculado incluye valores inferiores a 2.0 y presenta una concentración destacada en torno a 6.5.
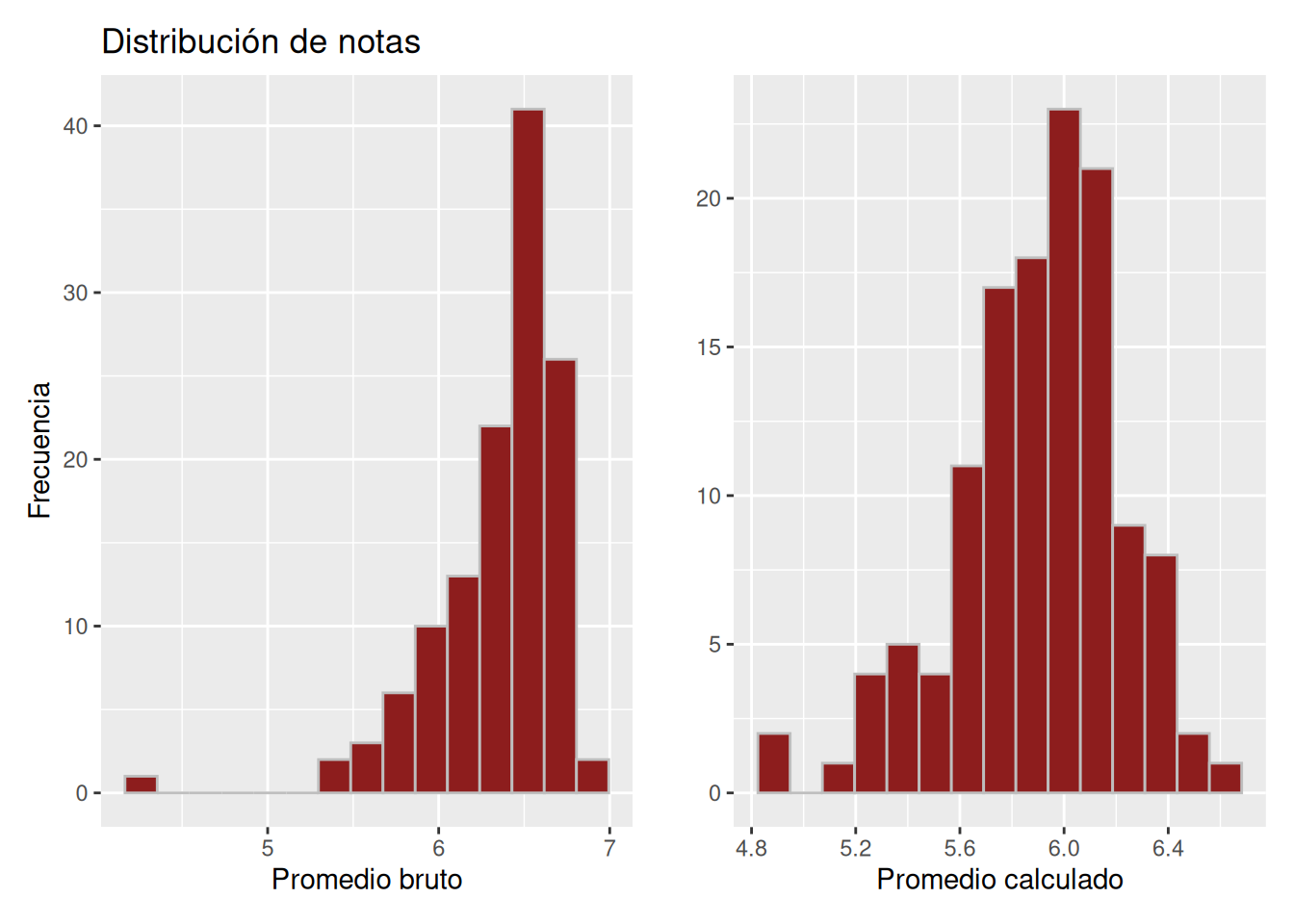
Finalmente, en Figura 5.6, la distribución del promedio bruto adopta una forma escalonada ascendente entre 5.5 y 7.0, aunque se identifica un valor atípico cercano a 4.0 en el extremo inferior. El promedio calculado, en cambio, agrupa sus observaciones aproximadamente entre 4.8 y 6.4, mostrando una forma similar a la del promedio bruto en la zona central de la distribución.
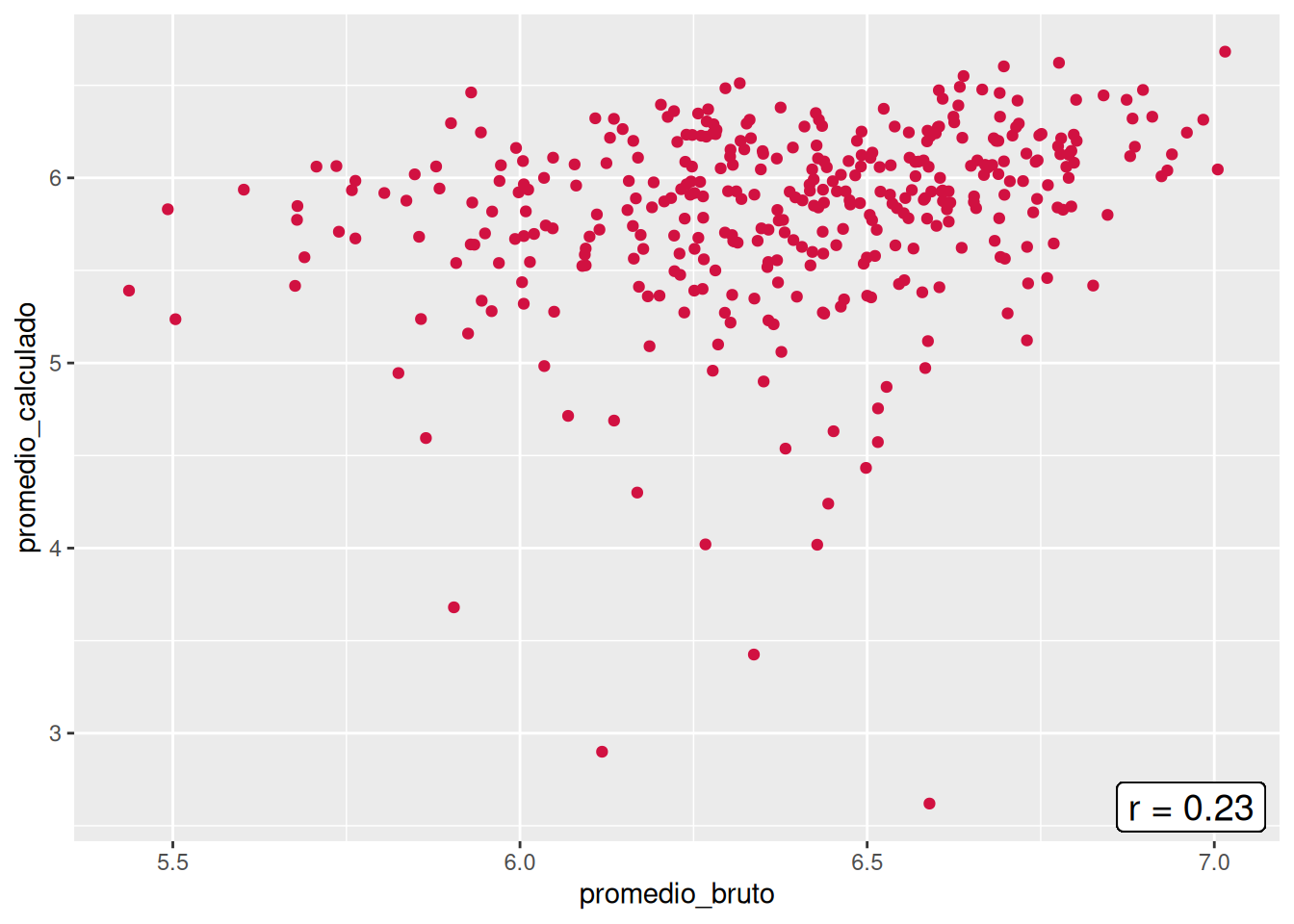
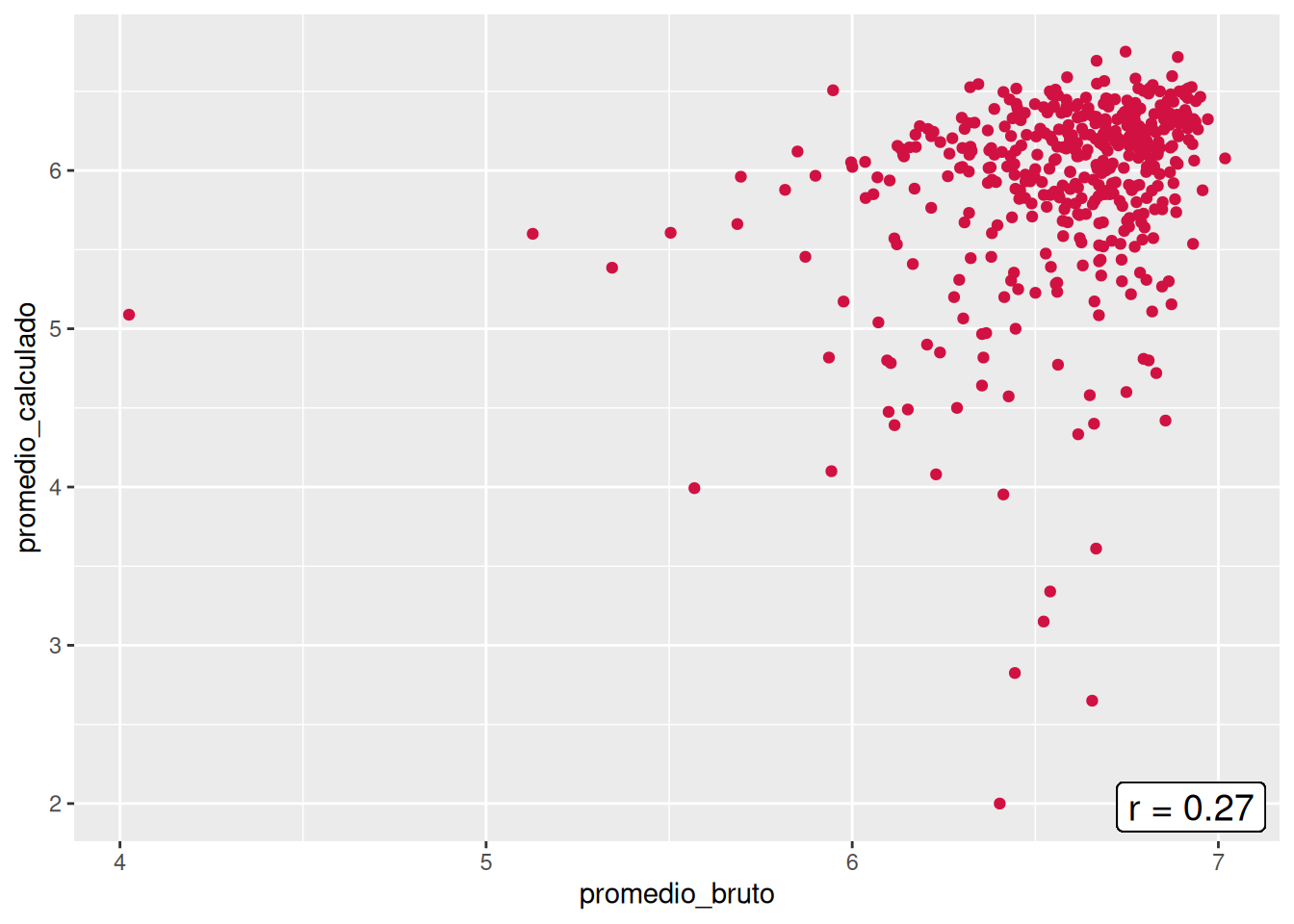
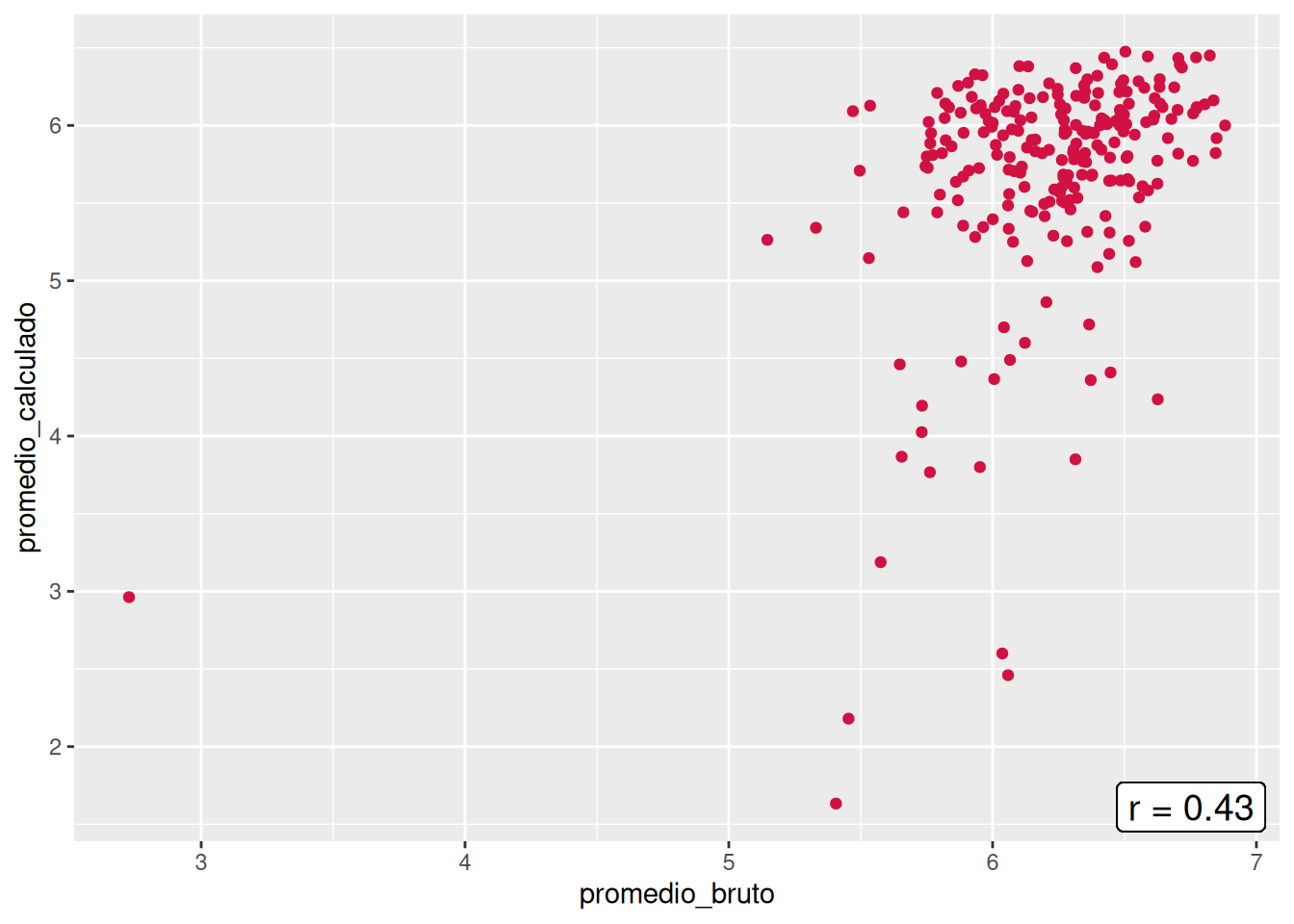
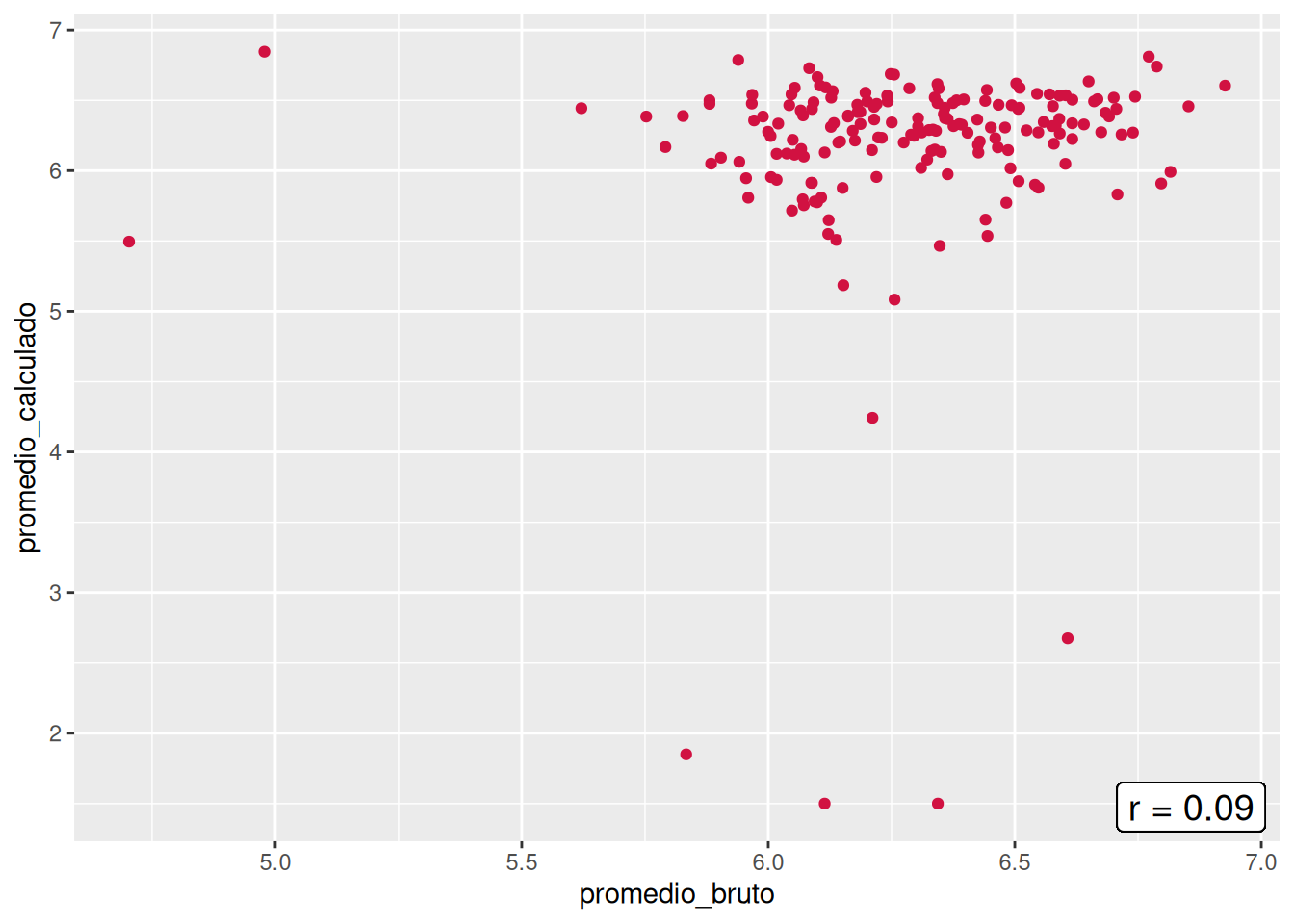
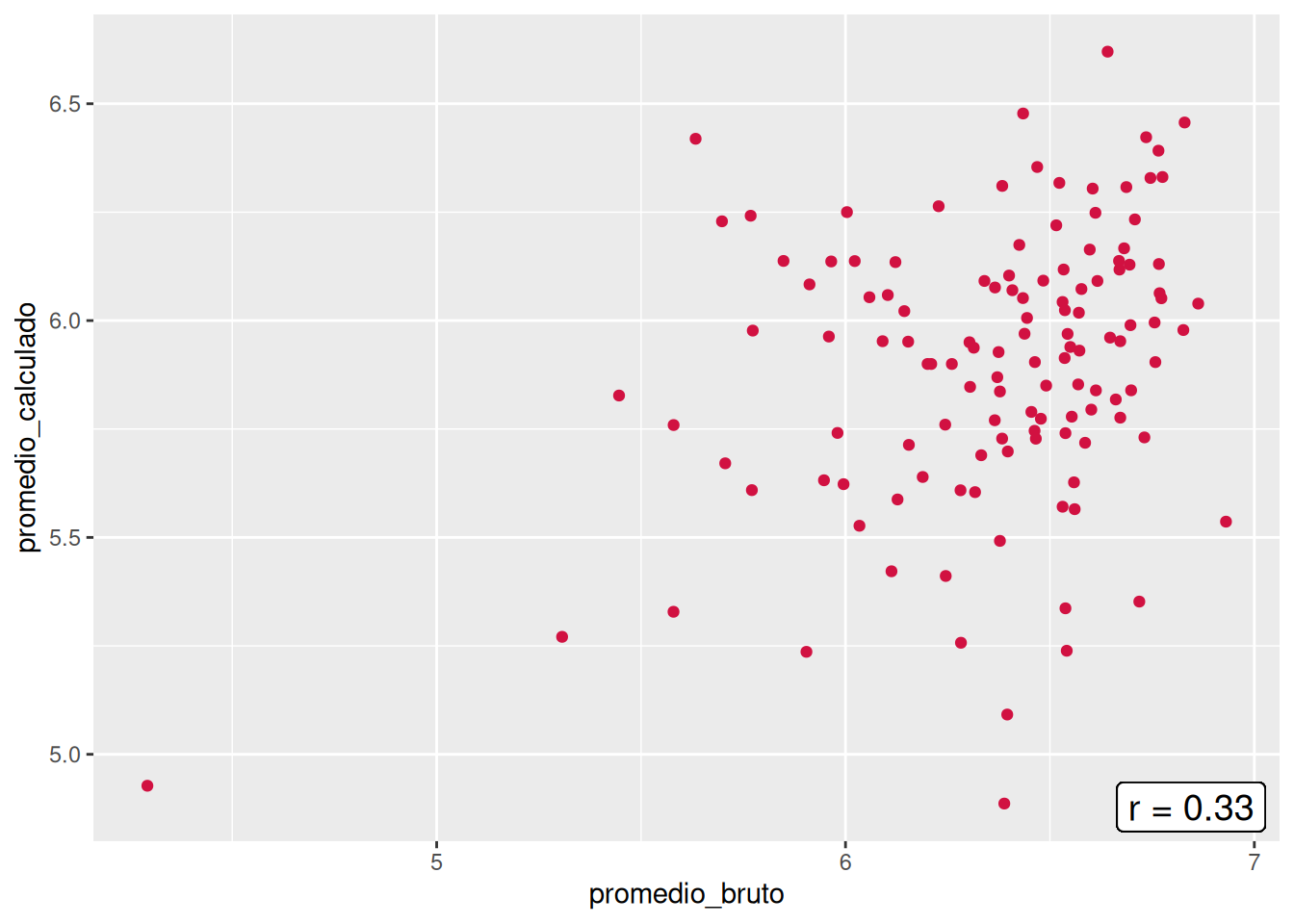
En el panel se presentan las asociaciones entre el promedio bruto y el promedio calculado por cada carrera. Todas las carreras comparten la similitud de no tener un patrón lineal en cuanto a las notas, lo cual se condice con las bajas correlaciones, donde la más alta es la de Trabajo social con un \(r = 0.43\), mientras que Educación Parvularia posee la más baja con un \(r = 0.09\). Si hacemos un enfoque en la carrera, los casos más llamativos son el de Psicología, que evidencia casos en donde el promedio calculado es superior al bruto, pero también el escenario contrario, y el de Trabajo Social, que demuestra una consistencia en que los promedios brutos son mayores al promedio calculado. En general, esto demuestra que existe una gran inconsistencia entre las notas del promedio por defecto y el promedio calculado a partir de las notas por curso a nivel de facultad.
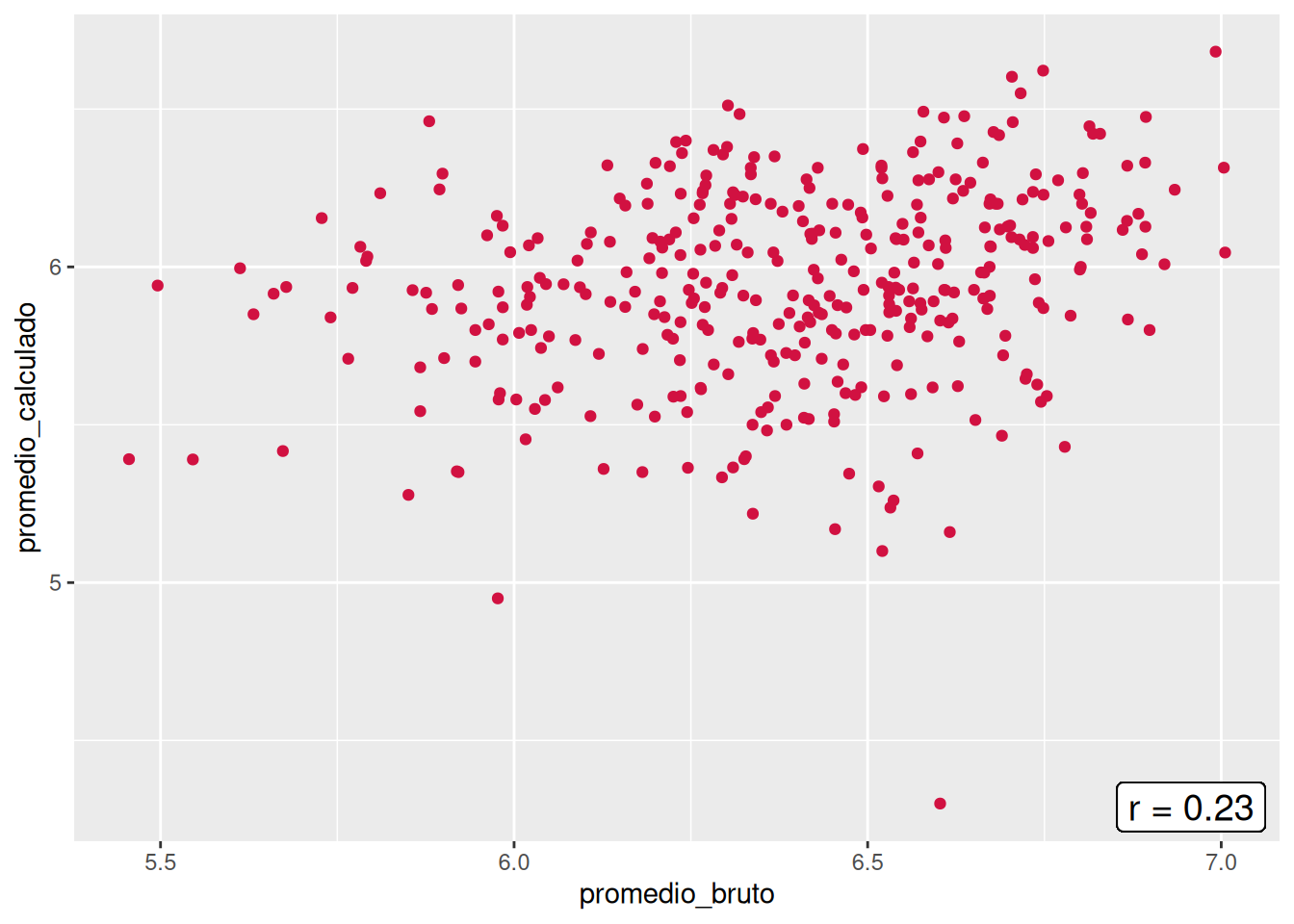
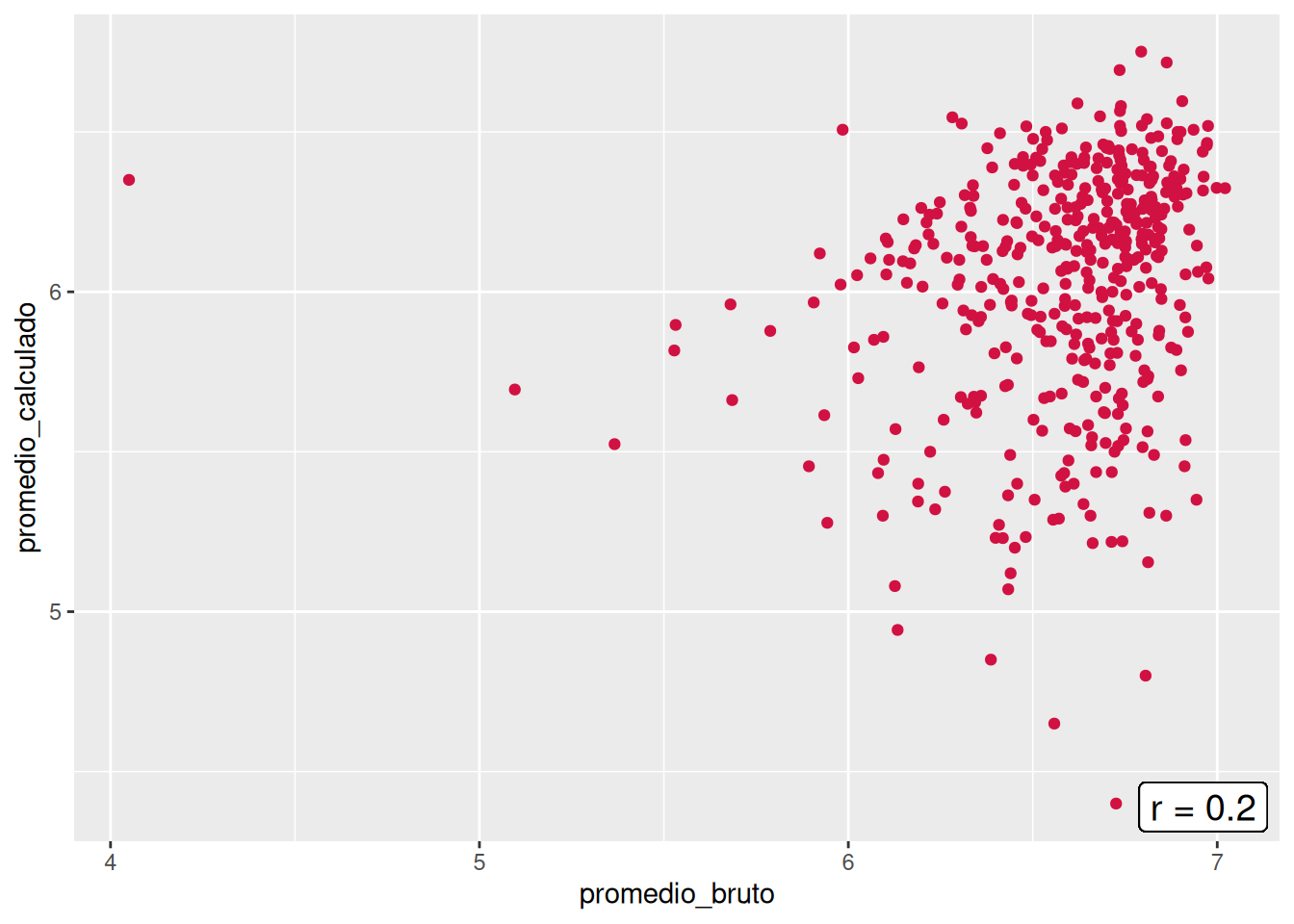
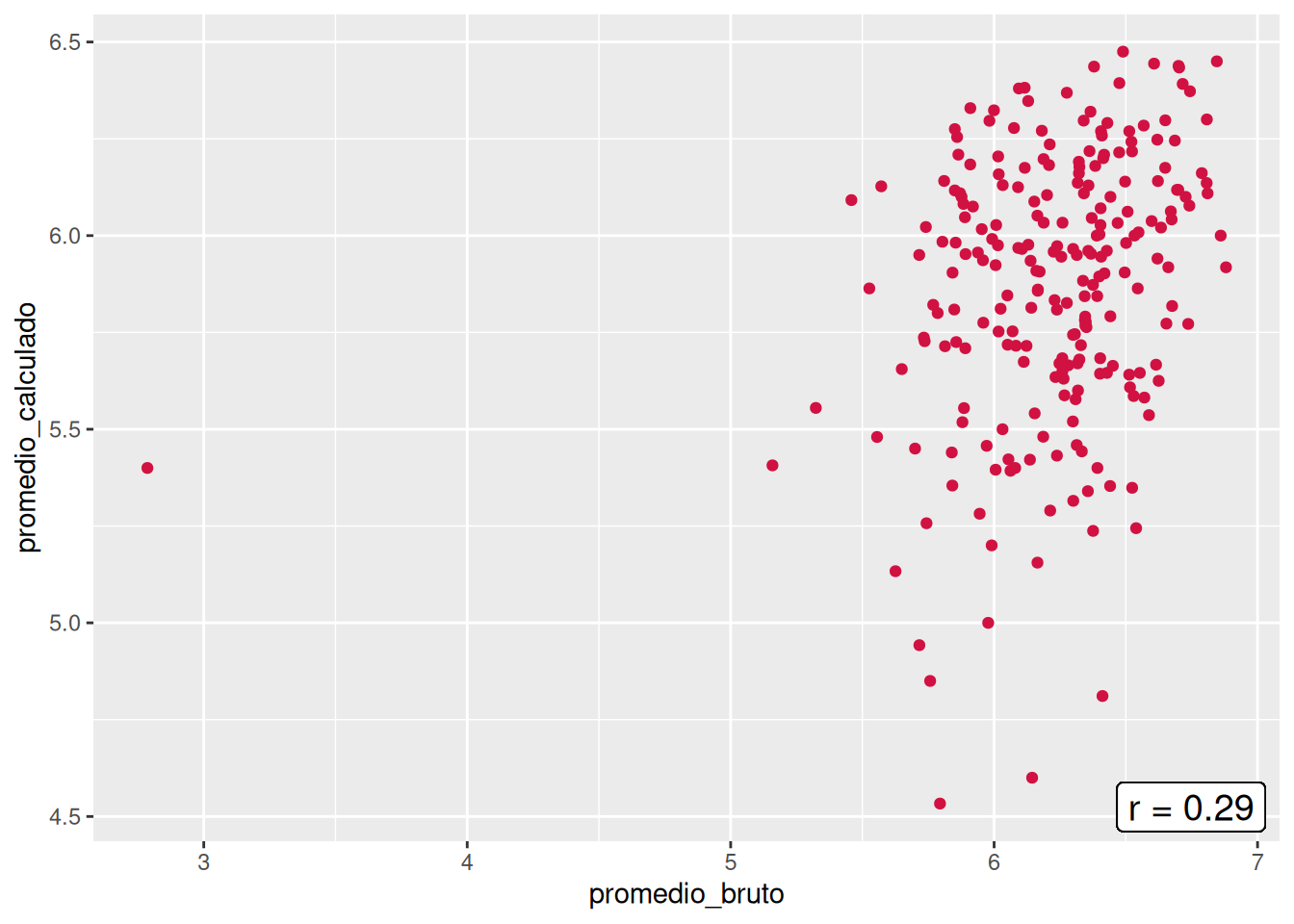
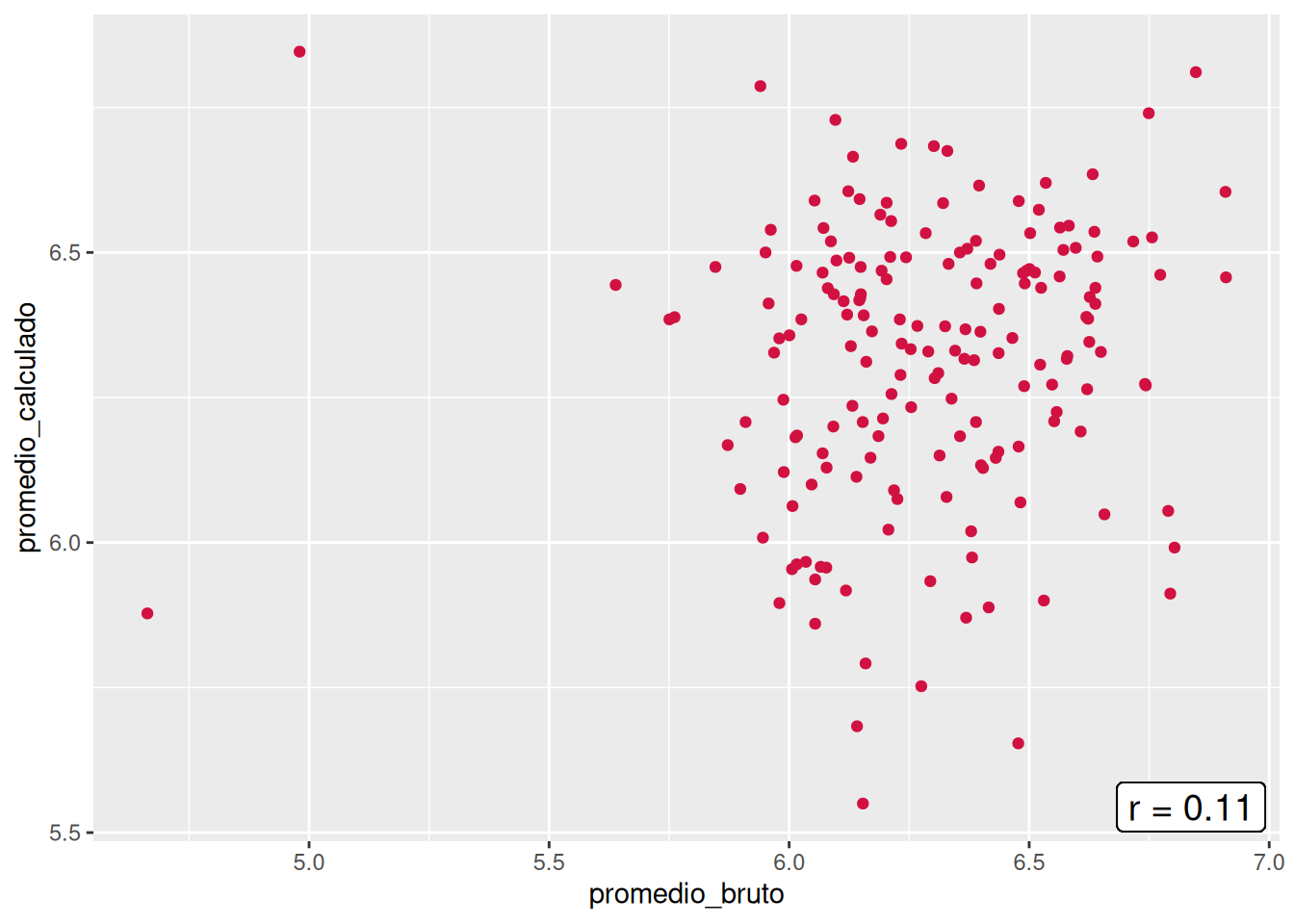
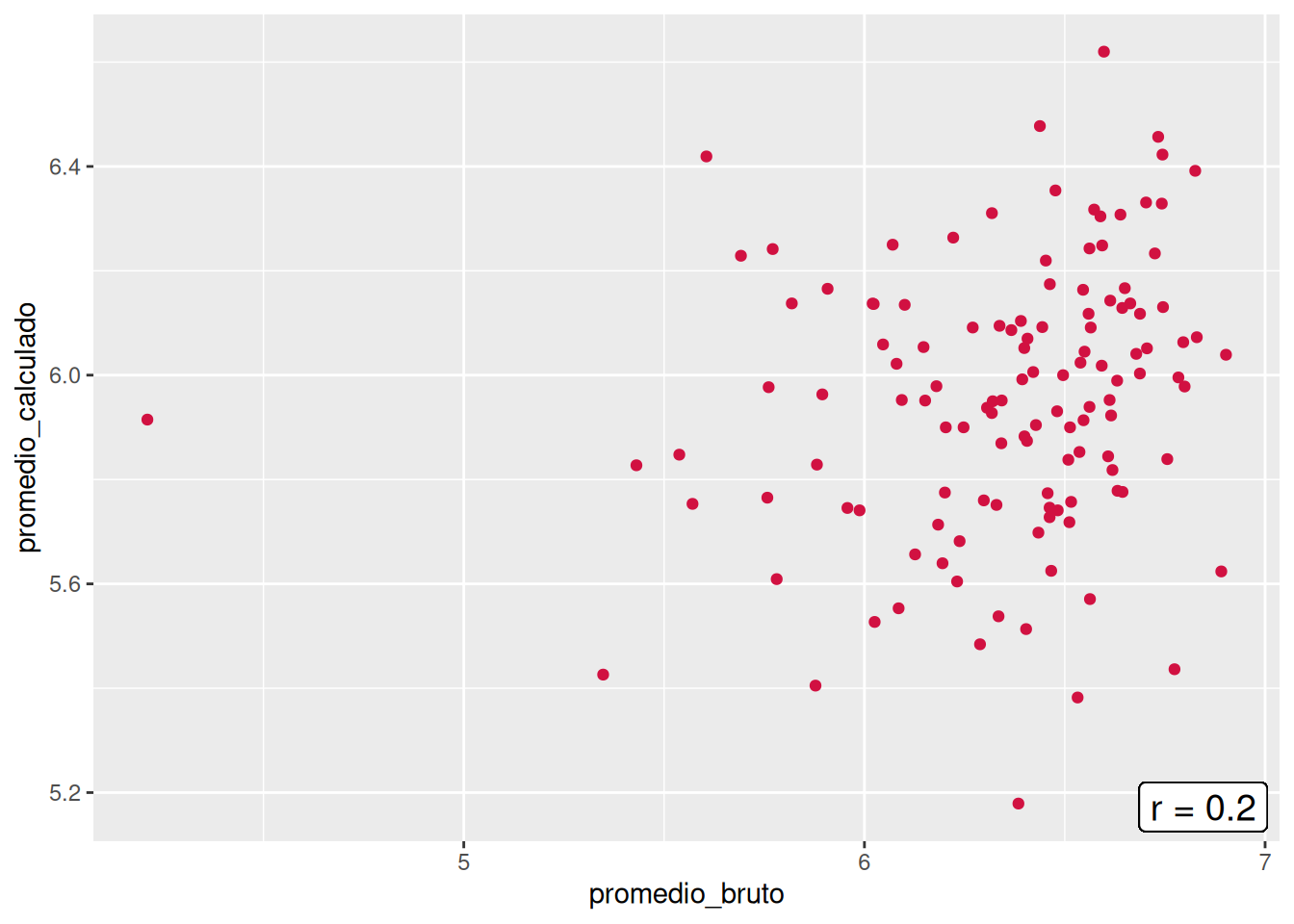
En orden de encontrar de despejar incógnitas respecto a las diferencias entre los promedios brutos y calculados, se construyeron los gráficos de nube pero con la diferencia que el promedio calculado sólo considera los ramos aprobados (> 4.0). Al aplicar esto, las correlaciones de tres de las cinco carreras disminuyeron (Psicología, Trabajo Social y Antropología), mientras que Sociología se mantuvo y Educación Parvularia aumentó. Aun así, el panorama no entrega una mejora, sino un empeoramiento respecto a la asociación entre el promedio bruto y el calculado, pues todos los \(r\) varían entre 0.11 y 0.29. Con ello, se descarta que la consideración de cursos desaprobados y aprobados sea el causante de las bajas correlaciones.
Considerando el análisis de dos pasos, hay dos hallazgos que resaltar: la inconsistencia de observaciones entre la base con el promedio bruto y las notas por curso (1), y además la diferencia entre el promedio bruto y el promedio calculado (2), lo cual evidencia discrepancias en los cálculos entre uno y otro.
Para comprender porqué se genera el primer obstáculo, se necesita recurrir a más información de la construcción de las bases de datos, pues de momento no hay evidencia para hipotetizar. Respecto al segundo hallazgo, una hipótesis plausible para explicar el desajuste de los resultados es que los cursos están ponderados por créditos, y el promedio calculado a partir de las notas desagregadas considera un peso equivalente de todos los cursos, por lo que naturalmente dará un resultado distinto a un promedio que viene ponderado por defecto. Actualmente no contamos con una variable que permita aplicar una ponderación a cada curso. Por ello, es necesario contar con la cantidad de créditos que vale cada ramo, con el objetivo de trabajar con los datos más fidedignos posible, y así realizar un diagnóstico verificado en cuanto a la calidad de los datos.
Los análisis descriptivos permitieron observar que existen diferencias en las carreras en cuanto a los casos disponibles para el estudio, así como en las notas. En este contexto, carreras como Educación Parvularia y Antropología fueron las que tienen la menor cantidad de casos, aunque es necesario seguir indagando en la razón de la pérdida para esta última carrera. Además, quedó demostrado que el promedio que se calcula a partir de las notas de los cursos es consistentemente menor al promedio bruto en todas las carreras, lo cual se visualizó en la manera en que se distribuyen las notas a partir de los histogramas.
En la asociación del promedio bruto con el promedio calculado, se evidenció como un síntoma general de todas las carreras de la facultad la baja correlación entre estas variables, sin encontrar un patrón claro en su comportamiento. Con tal de indagar más allá, se replicó el análisis pero solamente considerando los cursos aprobados, pero los resultados mejoraron sólo en una de las cinco carreras, que fue Educación Parvularia. Bajo este panorama, se puede confirmar que existe una inconsistencia entre el promedio por defecto de UCampus y el promedio construido a partir de las notas de cursos.
Para proseguir con el estudio, se propone lo siguiente: Primero, priorizar en el análisis el promedio calculado, pues, tomando en cuenta que es la información a la que tenemos acceso directo, y sabemos el porqué de los resultados, es una fuente más confiable de análisis que el promedio bruto. Segundo, comenzar con cruces (tanto gráficos como tablas) entre las calificaciones académicas y las variables disponibles, tanto exógenas como endógenas.