Código
pacman::p_load(codebook, skimr, rlang, here, tidyverse)pacman::p_load(codebook, skimr, rlang, here, tidyverse)base_madre <- readRDS("../../../../input/data/proc_data/base_madre.rds")libro_codigos <- base_madre %>%
select(-starts_with("curso_"))
codebook(libro_codigos)Dataset name: libro_codigos
The dataset has N=1983 rows and 19 columns. 1605 rows have no missing values on any column.
|
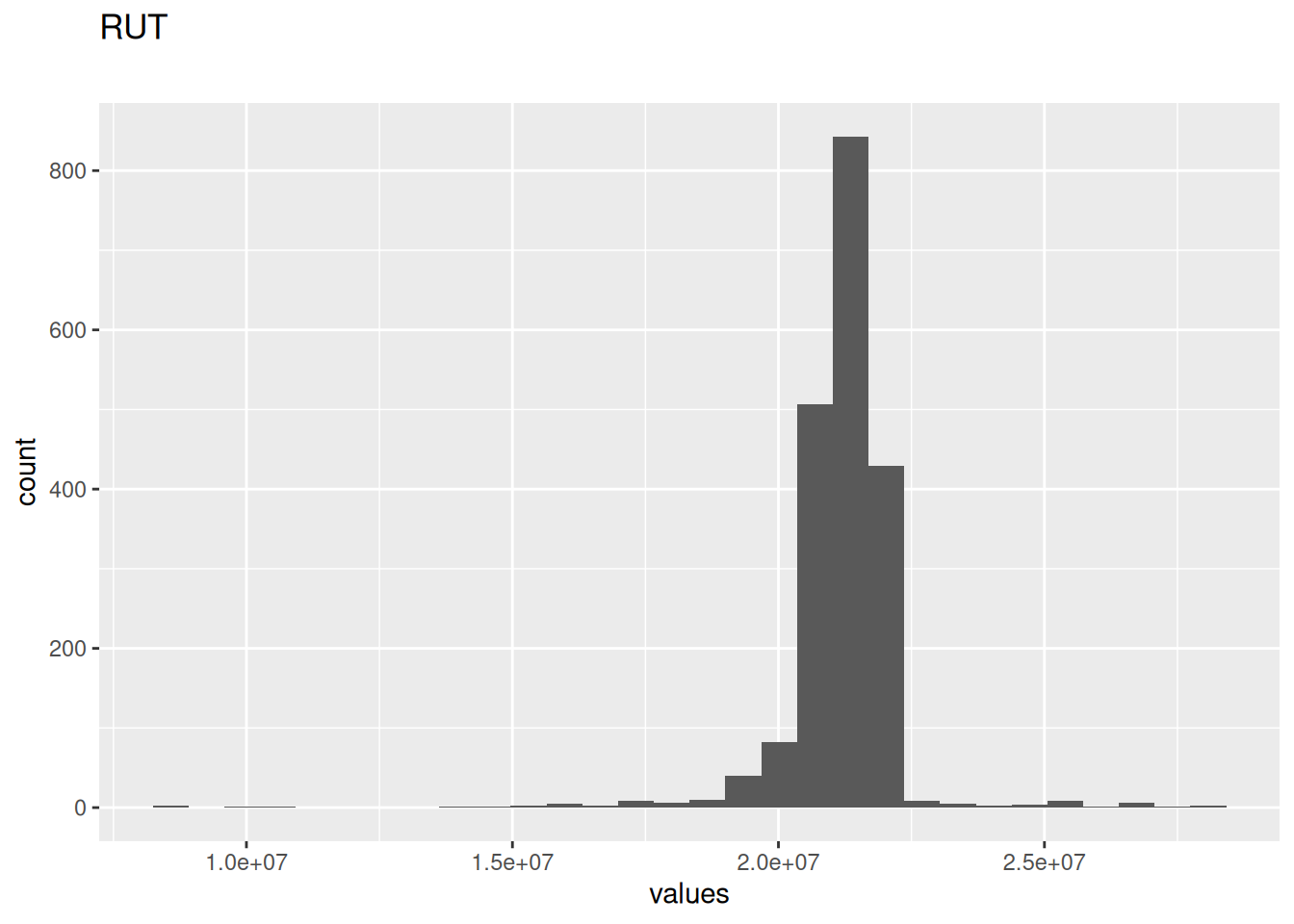
1 missing values.
| name | data_type | n_missing | complete_rate | min | median | max | mean | sd | hist | label |
|---|---|---|---|---|---|---|---|---|---|---|
| RUT | numeric | 1 | 0.9994957 | 8578025 | 2.1e+07 | 2.8e+07 | 21189279 | 1112119 | ▁▁▁▇▁ | NA |
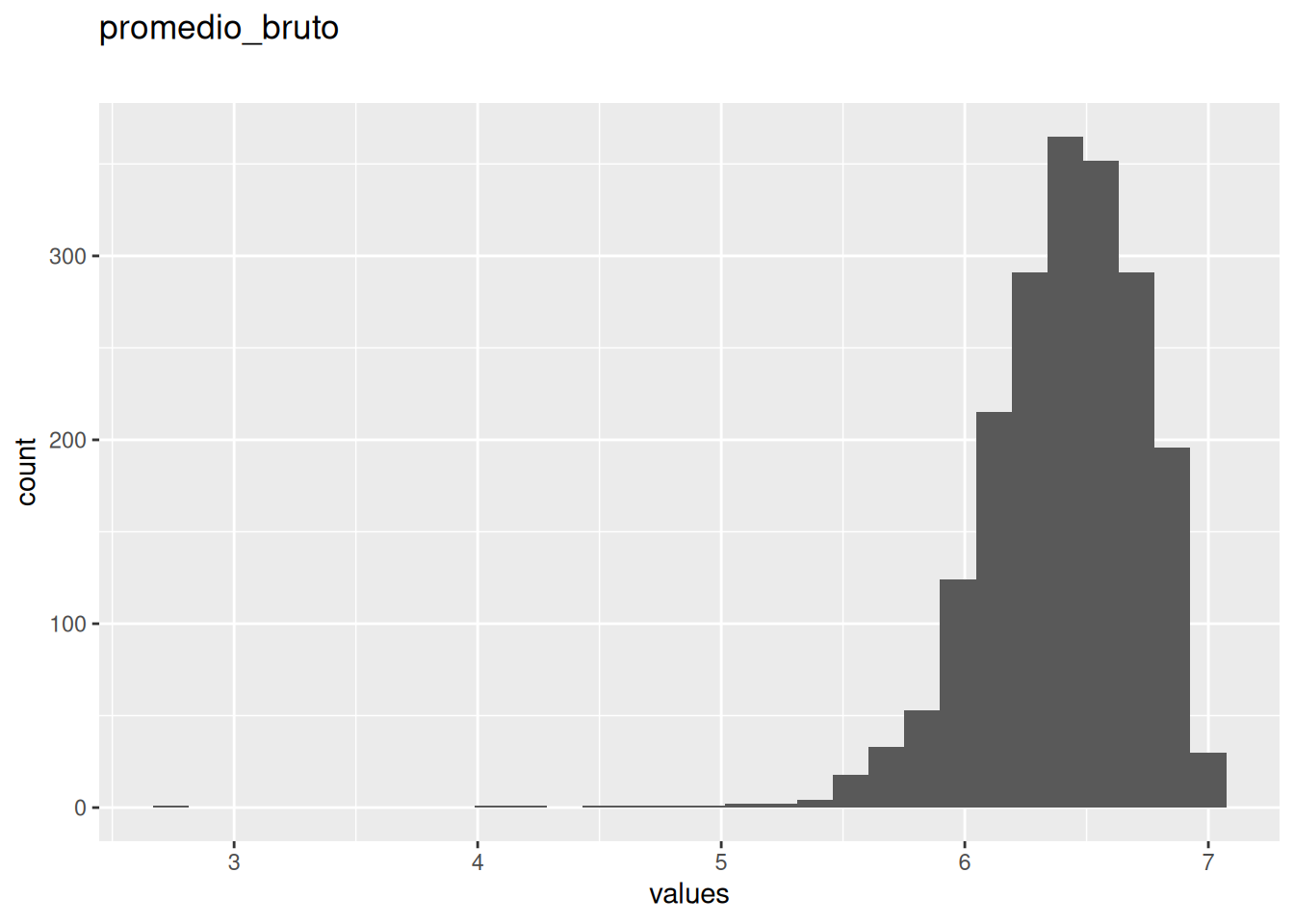
0 missing values.
| name | data_type | n_missing | complete_rate | min | median | max | mean | sd | hist | label |
|---|---|---|---|---|---|---|---|---|---|---|
| promedio_bruto | numeric | 0 | 1 | 2.7 | 6.5 | 7 | 6.403999 | 0.3343942 | ▁▁▁▂▇ | NA |
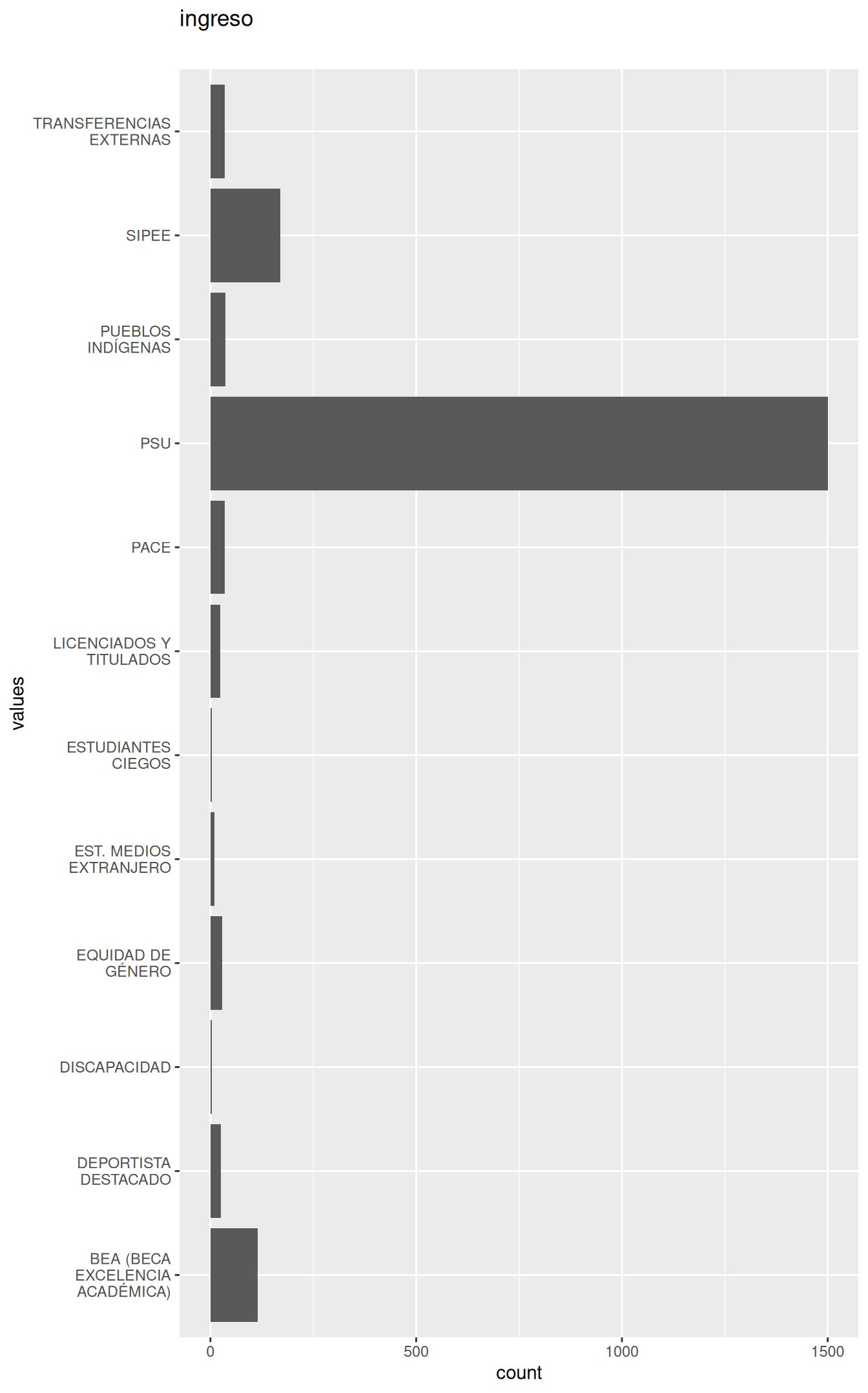
0 missing values.
| name | data_type | n_missing | complete_rate | n_unique | empty | min | max | whitespace | label |
|---|---|---|---|---|---|---|---|---|---|
| ingreso | character | 0 | 1 | 12 | 0 | 3 | 31 | 0 | NA |
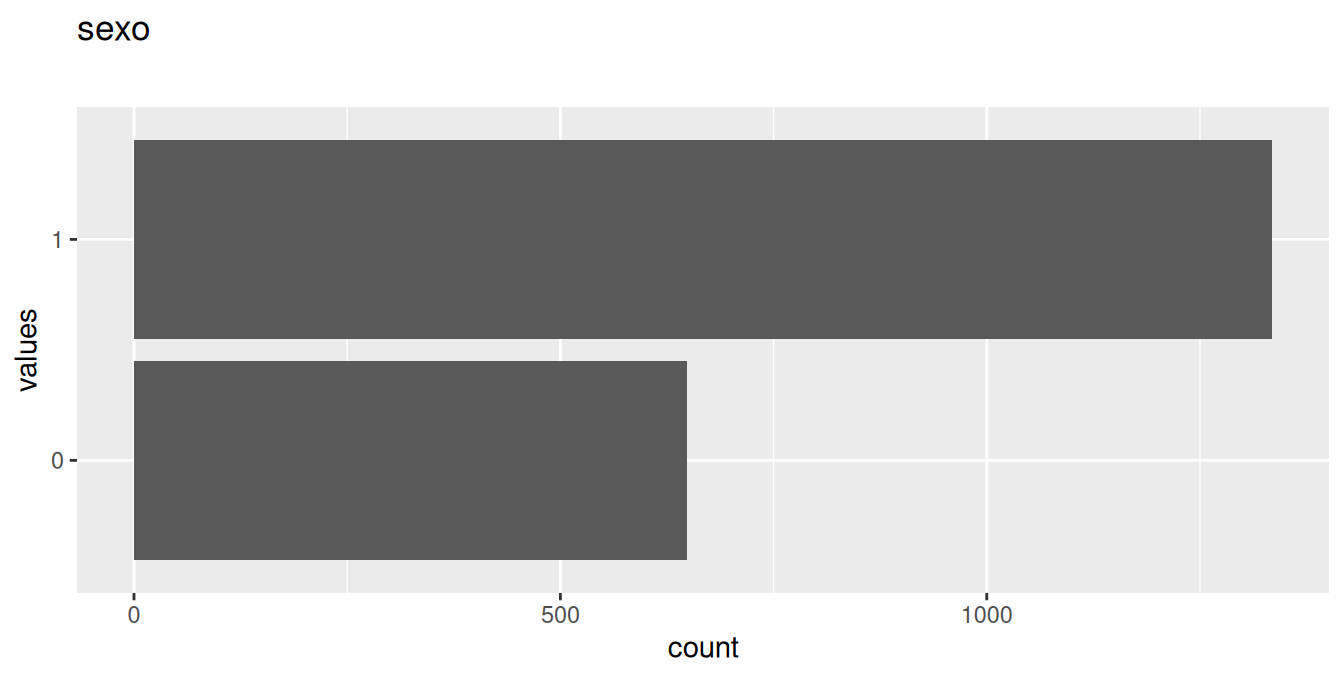
0 missing values.
| name | data_type | ordered | value_labels | n_missing | complete_rate | n_unique | top_counts | label |
|---|---|---|---|---|---|---|---|---|
| sexo | factor | FALSE | 1. 0, 2. 1 |
0 | 1 | 2 | 1: 1335, 0: 648 | NA |
0 missing values.
| name | data_type | n_missing | complete_rate | n_unique | empty | min | max | whitespace | label |
|---|---|---|---|---|---|---|---|---|---|
| NACIONALIDAD | character | 0 | 1 | 21 | 0 | 7 | 28 | 0 | NA |
286 missing values.
| name | data_type | n_missing | complete_rate | n_unique | empty | min | max | whitespace | label |
|---|---|---|---|---|---|---|---|---|---|
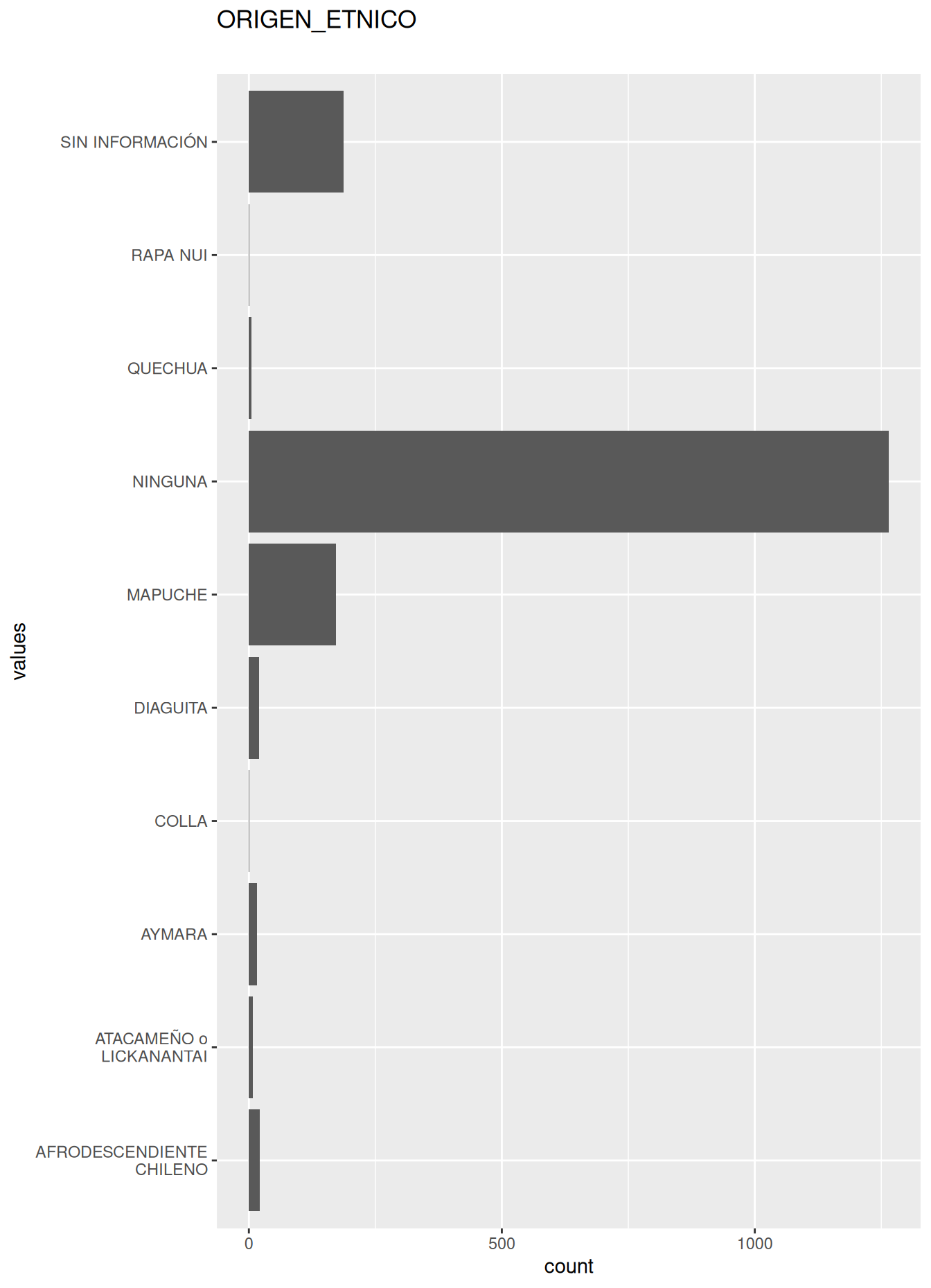
| ORIGEN_ETNICO | character | 286 | 0.8557741 | 10 | 0 | 5 | 24 | 0 | NA |
0 missing values.
| name | data_type | n_missing | complete_rate | n_unique | empty | min | max | whitespace | label |
|---|---|---|---|---|---|---|---|---|---|
| COMUNA_ORIGEN | character | 0 | 1 | 147 | 0 | 3 | 20 | 0 | NA |
0 missing values.
| name | data_type | n_missing | complete_rate | n_unique | empty | min | max | whitespace | label |
|---|---|---|---|---|---|---|---|---|---|
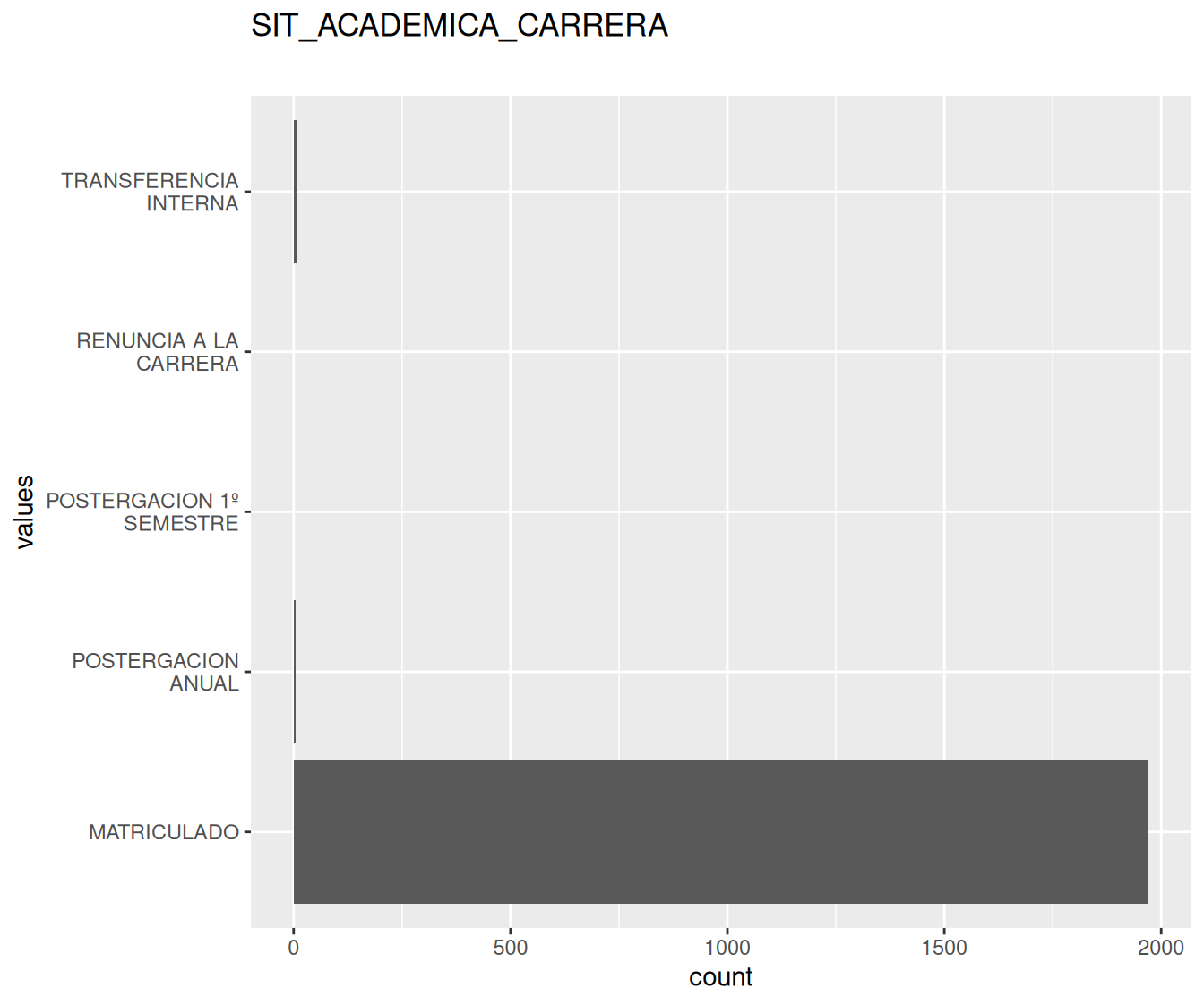
| SIT_ACADEMICA_CARRERA | character | 0 | 1 | 5 | 0 | 11 | 26 | 0 | NA |
0 missing values.
| name | data_type | n_missing | complete_rate | n_unique | empty | min | max | whitespace | label |
|---|---|---|---|---|---|---|---|---|---|
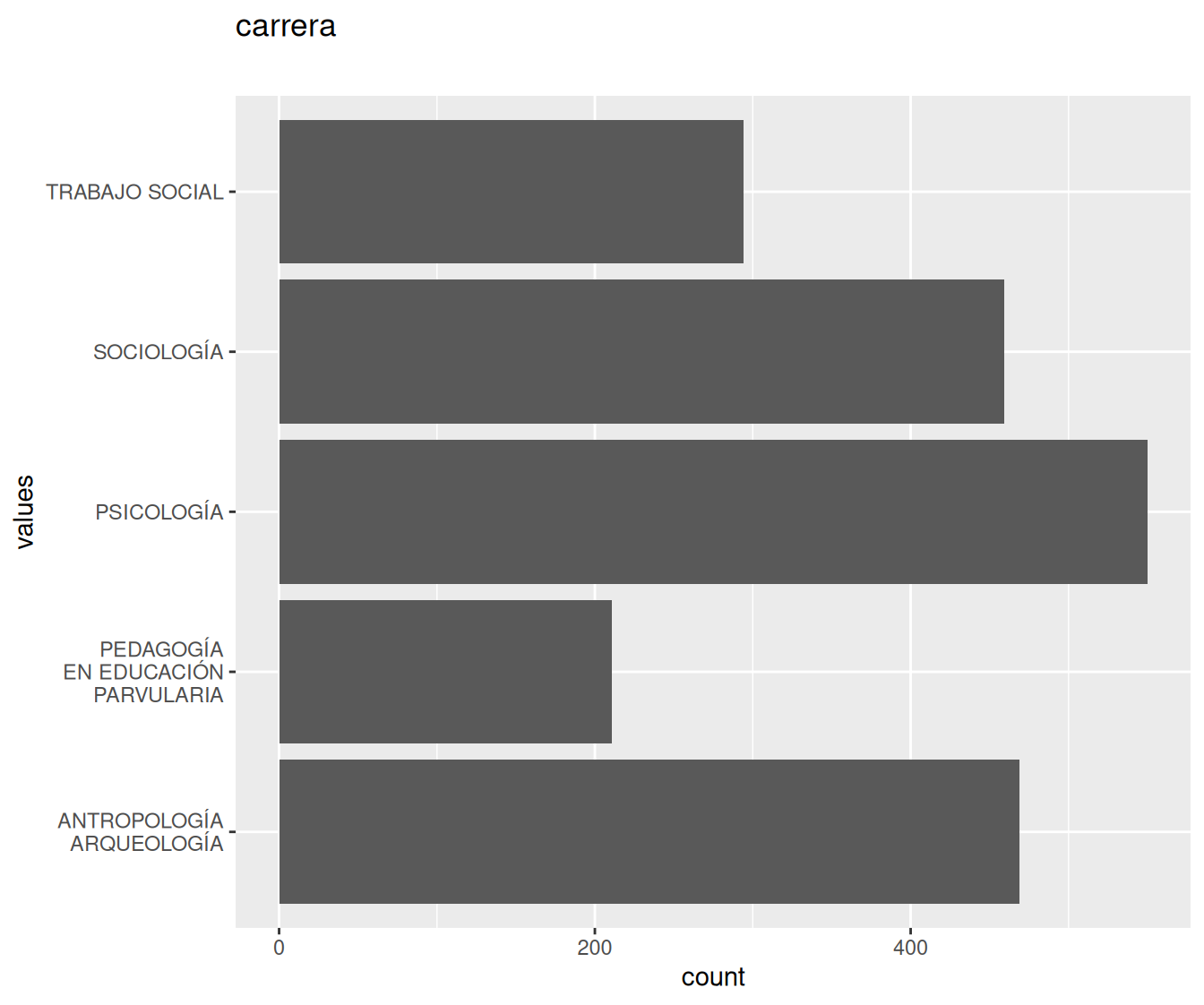
| carrera | character | 0 | 1 | 5 | 0 | 10 | 33 | 0 | NA |
1 missing values.
| name | data_type | ordered | value_labels | n_missing | complete_rate | n_unique | top_counts | label |
|---|---|---|---|---|---|---|---|---|
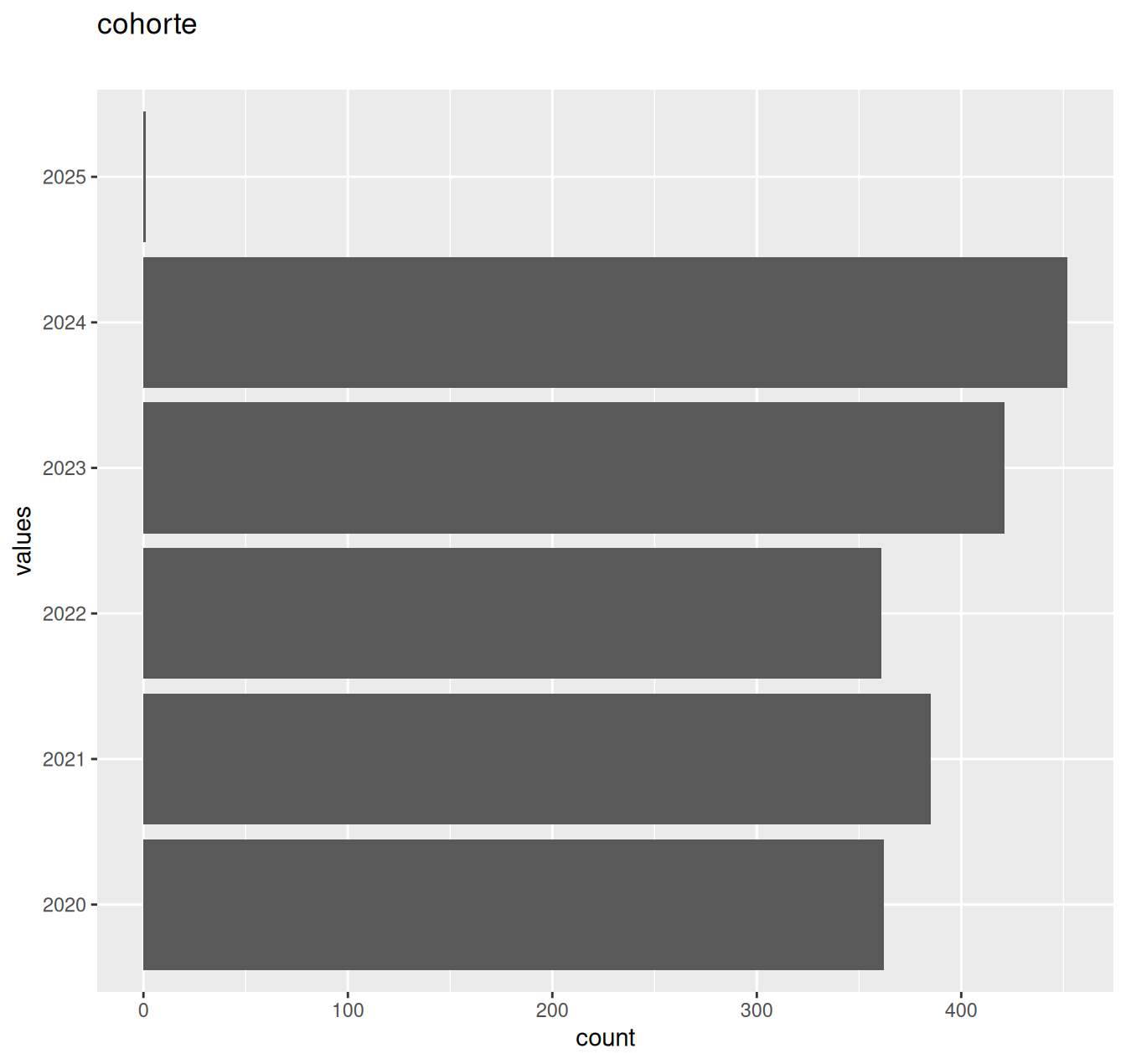
| cohorte | factor | FALSE | 1. 2020, 2. 2021, 3. 2022, 4. 2023, 5. 2024, 6. 2025 |
1 | 0.9994957 | 6 | 202: 452, 202: 421, 202: 385, 202: 362 | NA |
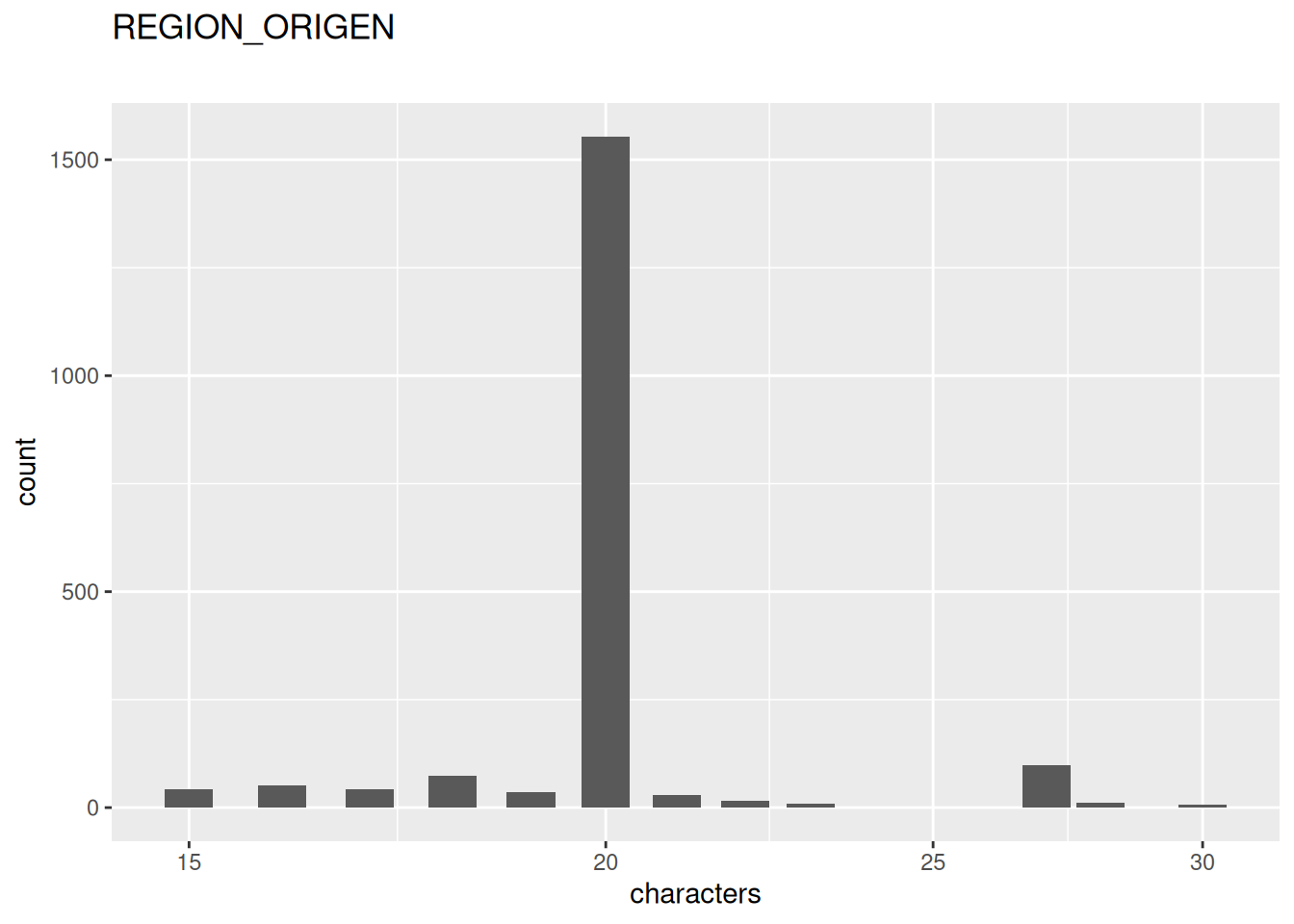
14 missing values.
| name | data_type | n_missing | complete_rate | n_unique | empty | min | max | whitespace | label |
|---|---|---|---|---|---|---|---|---|---|
| REGION_ORIGEN | character | 14 | 0.99294 | 22 | 0 | 15 | 30 | 0 | NA |
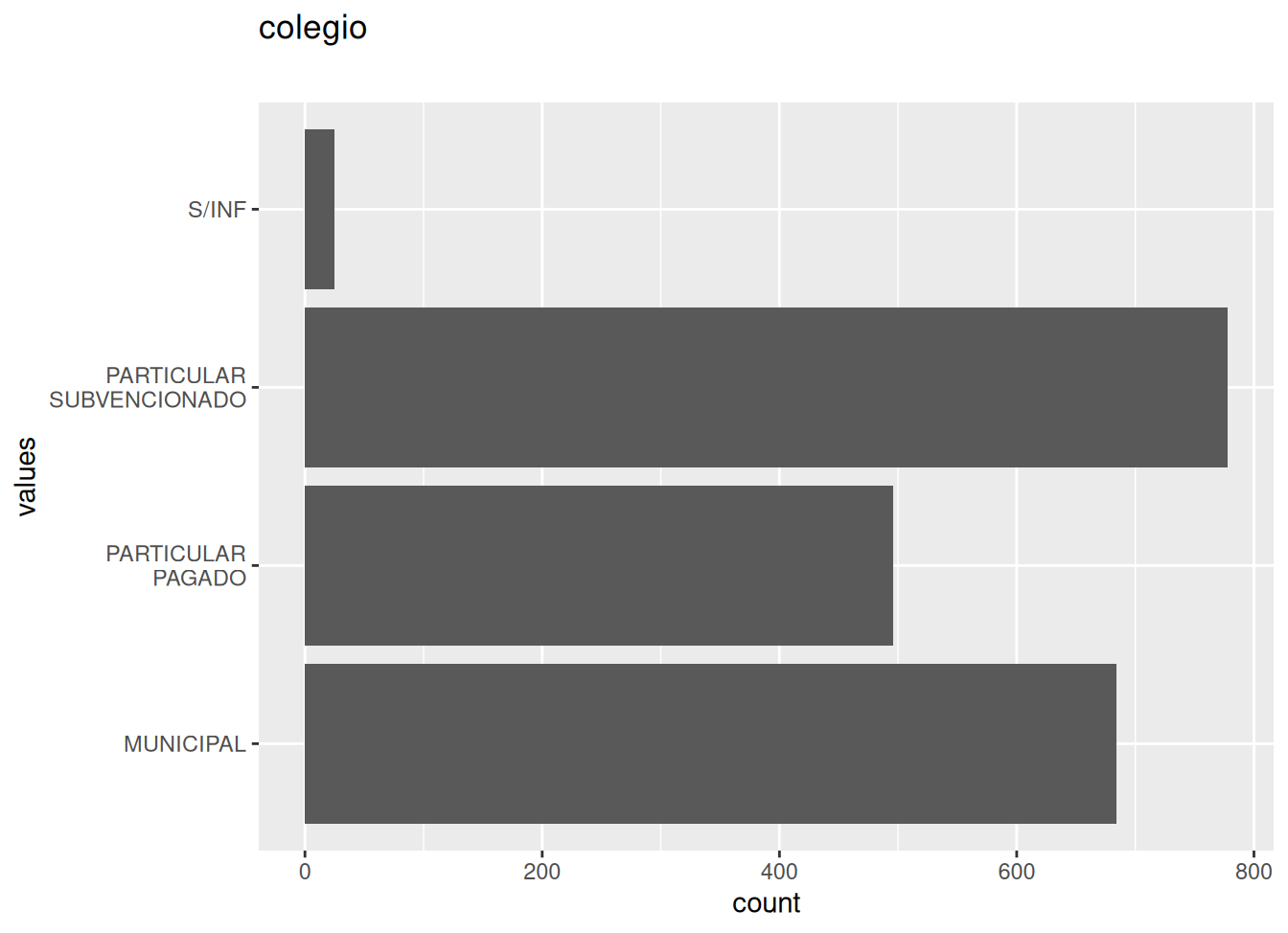
0 missing values.
| name | data_type | n_missing | complete_rate | n_unique | empty | min | max | whitespace | label |
|---|---|---|---|---|---|---|---|---|---|
| colegio | character | 0 | 1 | 4 | 0 | 5 | 24 | 0 | NA |
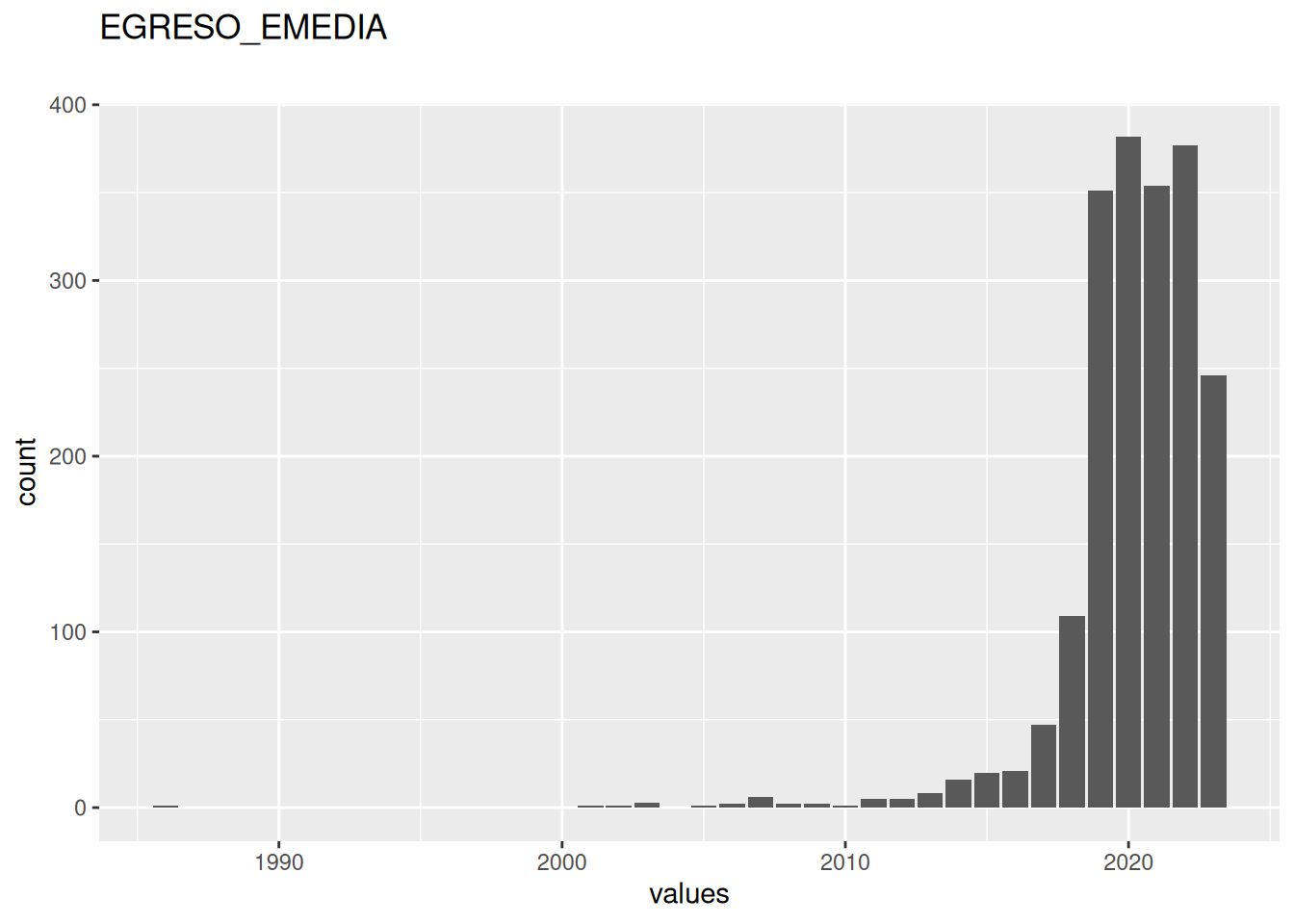
22 missing values.
| name | data_type | n_missing | complete_rate | min | median | max | mean | sd | hist | label |
|---|---|---|---|---|---|---|---|---|---|---|
| EGRESO_EMEDIA | numeric | 22 | 0.9889057 | 1986 | 2020 | 2023 | 2020.212 | 2.545078 | ▁▁▁▁▇ | NA |
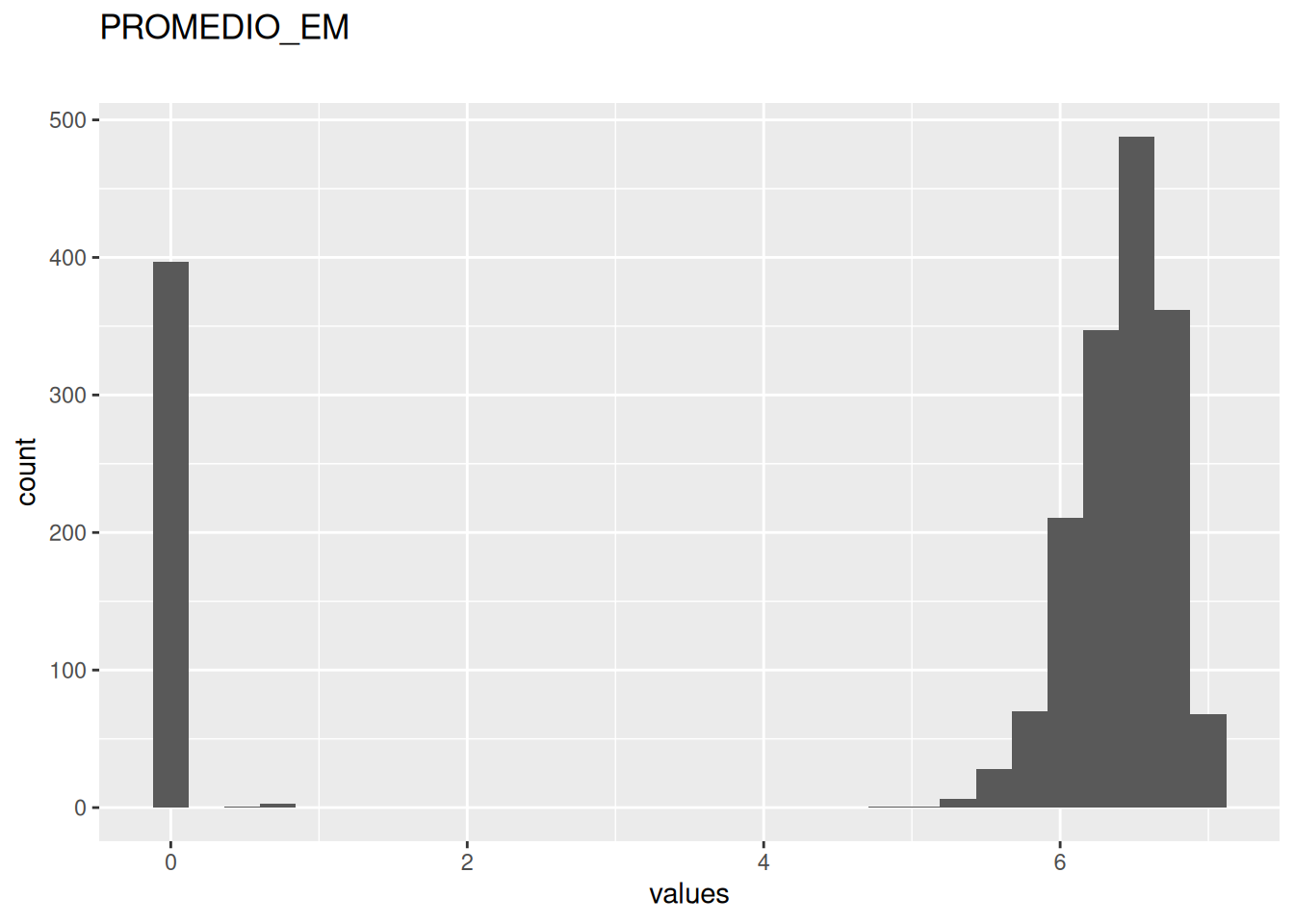
0 missing values.
| name | data_type | n_missing | complete_rate | min | median | max | mean | sd | hist | label |
|---|---|---|---|---|---|---|---|---|---|---|
| PROMEDIO_EM | numeric | 0 | 1 | 0 | 6.3 | 7 | 5.121377 | 2.591191 | ▂▁▁▁▇ | NA |
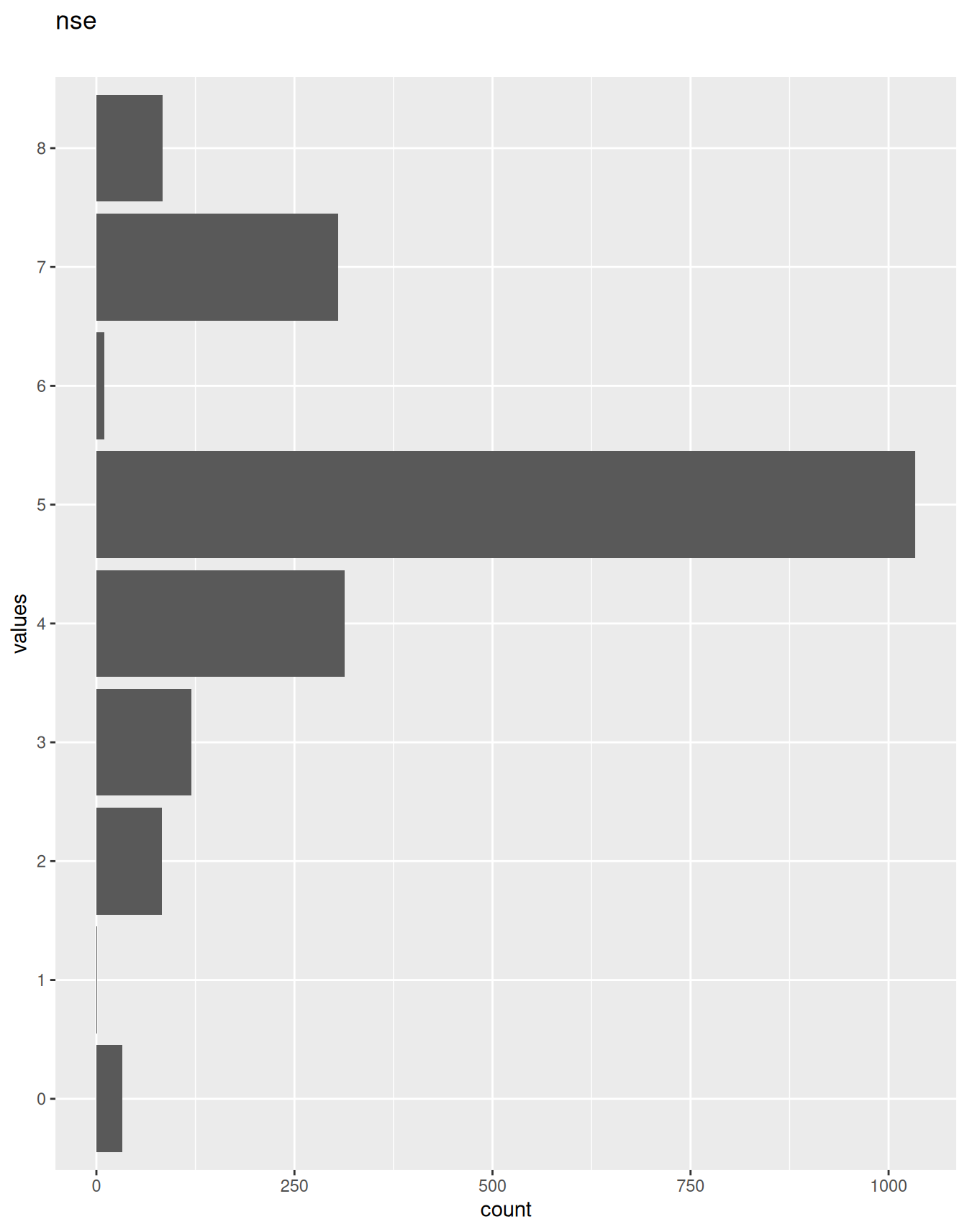
0 missing values.
| name | data_type | ordered | value_labels | n_missing | complete_rate | n_unique | top_counts | label |
|---|---|---|---|---|---|---|---|---|
| nse | factor | FALSE | 1. 0, 2. 1, 3. 2, 4. 3, 5. 4, 6. 5, 7. 6, 8. 7, 9. 8 |
0 | 1 | 9 | 5: 1034, 4: 313, 7: 305, 3: 120 | NA |
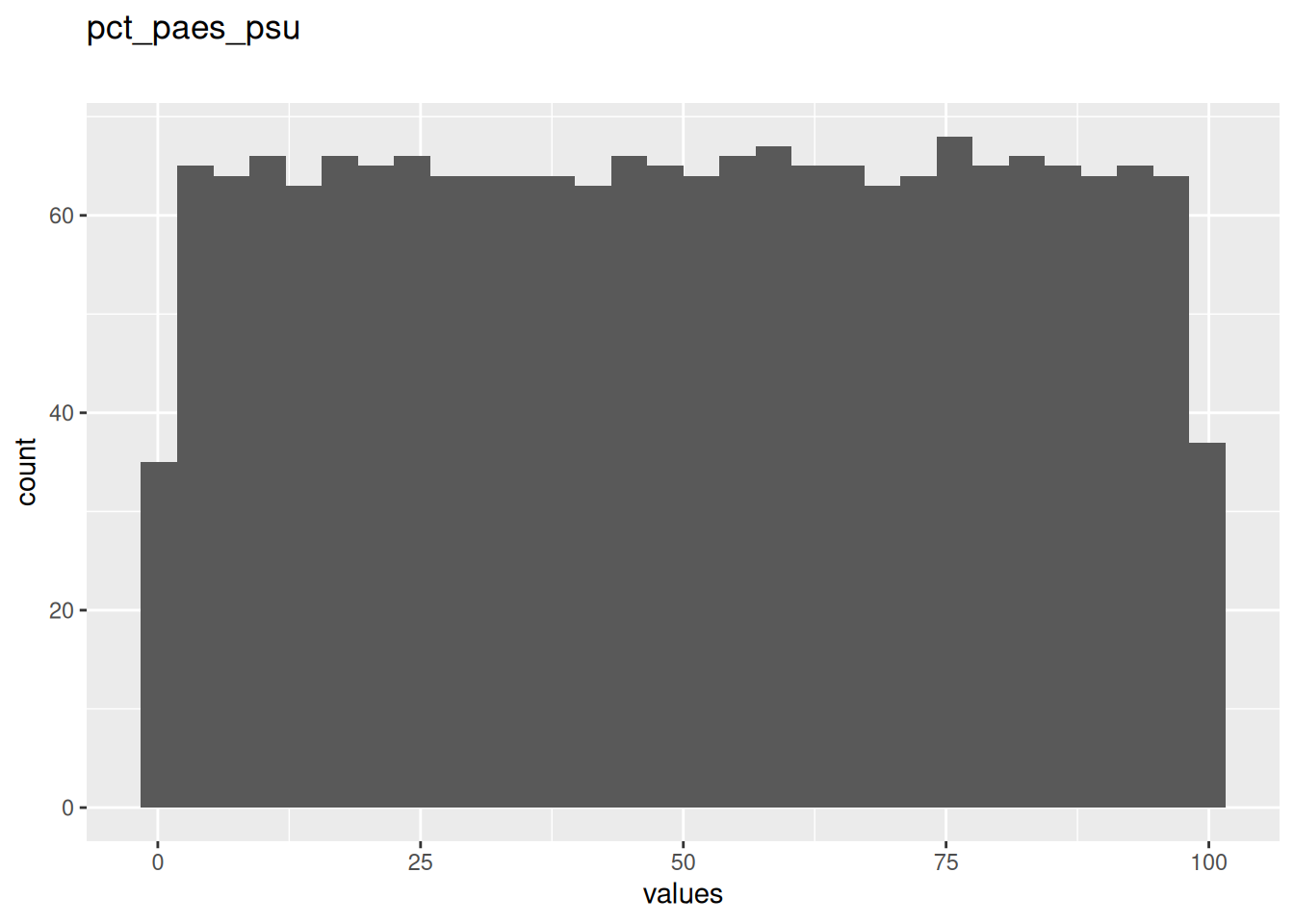
95 missing values.
| name | data_type | n_missing | complete_rate | min | median | max | mean | sd | hist | label |
|---|---|---|---|---|---|---|---|---|---|---|
| pct_paes_psu | numeric | 95 | 0.9520928 | 0.12 | 50 | 100 | 50.09019 | 28.91379 | ▇▇▇▇▇ | NA |
95 missing values.
| name | data_type | n_missing | complete_rate | min | median | max | mean | sd | hist | label |
|---|---|---|---|---|---|---|---|---|---|---|
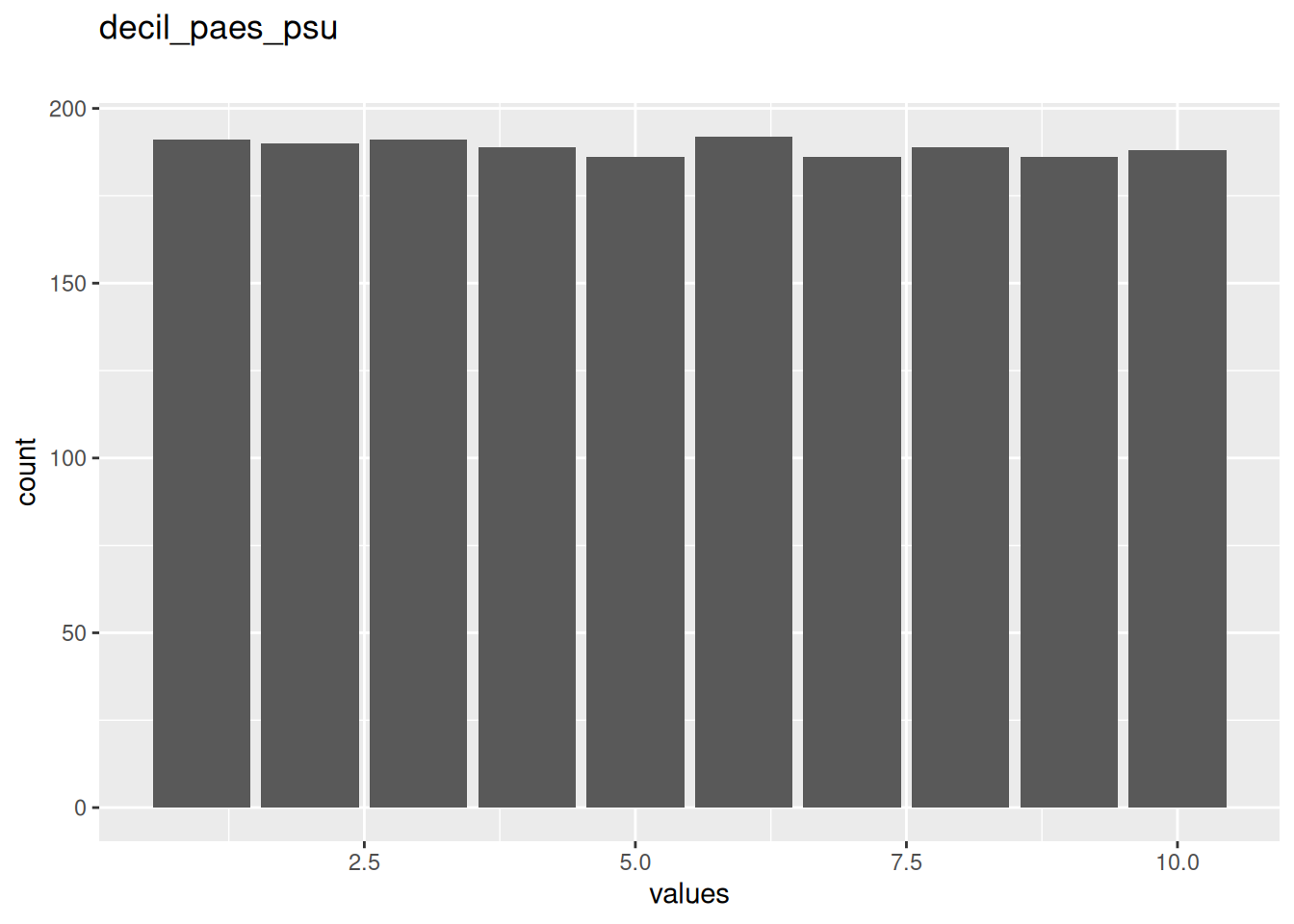
| decil_paes_psu | numeric | 95 | 0.9520928 | 1 | 5 | 10 | 5.481992 | 2.874646 | ▇▇▇▇▇ | NA |
0 missing values.
| name | data_type | n_missing | complete_rate | min | median | max | mean | sd | hist | label |
|---|---|---|---|---|---|---|---|---|---|---|
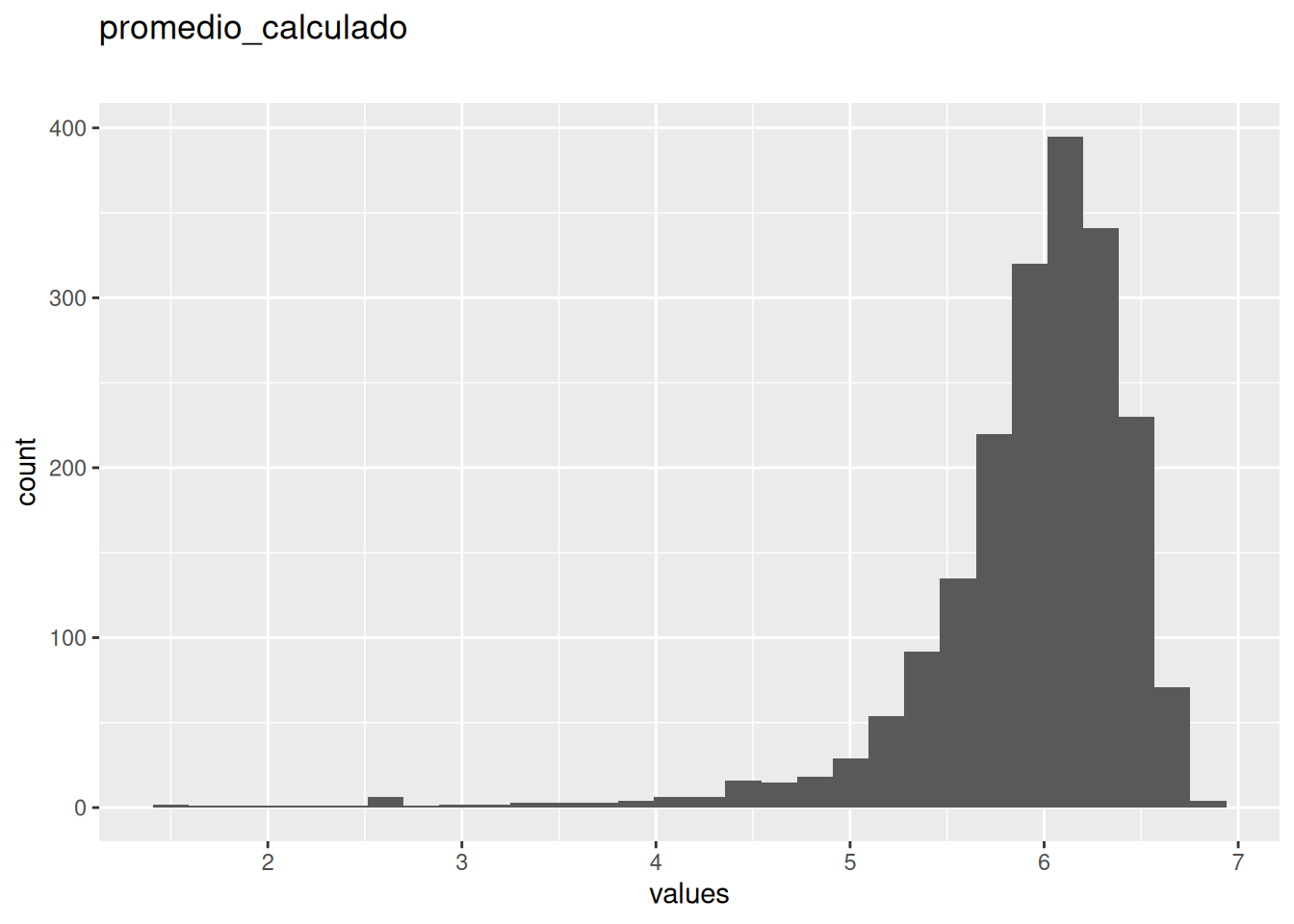
| promedio_calculado | numeric | 0 | 1 | 1.5 | 6 | 6.8 | 5.924136 | 0.5872285 | ▁▁▁▂▇ | NA |
0 missing values.
| name | data_type | n_missing | complete_rate | min | median | max | mean | sd | hist | label |
|---|---|---|---|---|---|---|---|---|---|---|
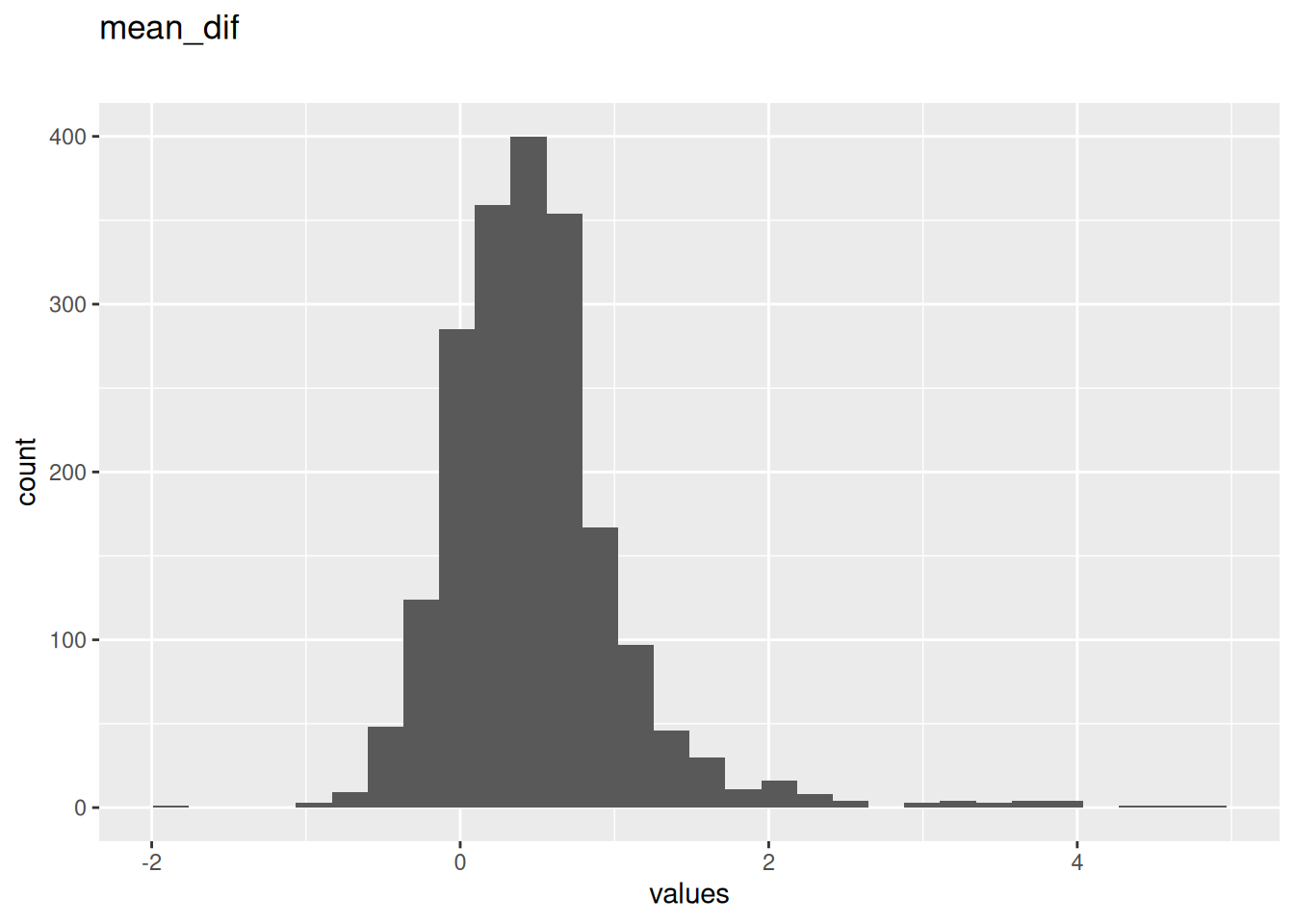
| mean_dif | numeric | 0 | 1 | -1.9 | 0.41 | 4.8 | 0.4798627 | 0.5973724 | ▁▇▂▁▁ | NA |
The following JSON-LD can be found by search engines, if you share this codebook publicly on the web.
{
"name": "libro_codigos",
"datePublished": "2025-12-29",
"description": "The dataset has N=1983 rows and 19 columns.\n1605 rows have no missing values on any column.\n\n\n## Table of variables\nThis table contains variable names, labels, and number of missing values.\nSee the complete codebook for more.\n\n|name |label | n_missing|\n|:---------------------|:-----|---------:|\n|RUT |NA | 1|\n|promedio_bruto |NA | 0|\n|ingreso |NA | 0|\n|sexo |NA | 0|\n|NACIONALIDAD |NA | 0|\n|ORIGEN_ETNICO |NA | 286|\n|COMUNA_ORIGEN |NA | 0|\n|SIT_ACADEMICA_CARRERA |NA | 0|\n|carrera |NA | 0|\n|cohorte |NA | 1|\n|REGION_ORIGEN |NA | 14|\n|colegio |NA | 0|\n|EGRESO_EMEDIA |NA | 22|\n|PROMEDIO_EM |NA | 0|\n|nse |NA | 0|\n|pct_paes_psu |NA | 95|\n|decil_paes_psu |NA | 95|\n|promedio_calculado |NA | 0|\n|mean_dif |NA | 0|\n\n### Note\nThis dataset was automatically described using the [codebook R package](https://rubenarslan.github.io/codebook/) (version 0.9.5).",
"keywords": ["RUT", "promedio_bruto", "ingreso", "sexo", "NACIONALIDAD", "ORIGEN_ETNICO", "COMUNA_ORIGEN", "SIT_ACADEMICA_CARRERA", "carrera", "cohorte", "REGION_ORIGEN", "colegio", "EGRESO_EMEDIA", "PROMEDIO_EM", "nse", "pct_paes_psu", "decil_paes_psu", "promedio_calculado", "mean_dif"],
"@context": "https://schema.org/",
"@type": "Dataset",
"variableMeasured": [
{
"name": "RUT",
"@type": "propertyValue"
},
{
"name": "promedio_bruto",
"@type": "propertyValue"
},
{
"name": "ingreso",
"@type": "propertyValue"
},
{
"name": "sexo",
"value": "1. 0,\n2. 1",
"@type": "propertyValue"
},
{
"name": "NACIONALIDAD",
"@type": "propertyValue"
},
{
"name": "ORIGEN_ETNICO",
"@type": "propertyValue"
},
{
"name": "COMUNA_ORIGEN",
"@type": "propertyValue"
},
{
"name": "SIT_ACADEMICA_CARRERA",
"@type": "propertyValue"
},
{
"name": "carrera",
"@type": "propertyValue"
},
{
"name": "cohorte",
"value": "1. 2020,\n2. 2021,\n3. 2022,\n4. 2023,\n5. 2024,\n6. 2025",
"@type": "propertyValue"
},
{
"name": "REGION_ORIGEN",
"@type": "propertyValue"
},
{
"name": "colegio",
"@type": "propertyValue"
},
{
"name": "EGRESO_EMEDIA",
"@type": "propertyValue"
},
{
"name": "PROMEDIO_EM",
"@type": "propertyValue"
},
{
"name": "nse",
"value": "1. 0,\n2. 1,\n3. 2,\n4. 3,\n5. 4,\n6. 5,\n7. 6,\n8. 7,\n9. 8",
"@type": "propertyValue"
},
{
"name": "pct_paes_psu",
"@type": "propertyValue"
},
{
"name": "decil_paes_psu",
"@type": "propertyValue"
},
{
"name": "promedio_calculado",
"@type": "propertyValue"
},
{
"name": "mean_dif",
"@type": "propertyValue"
}
]
}`